
AI agents have rapidly moved from experimental prototypes to critical components of real-world applications. In 2025, they are the backbone of customer support, document analysis, research, coding, and complex automations. But as LLM-powered agents grow in complexity by leveraging external tools, tracking memory, and managing multi-turn interactions, the big question is, how do we know if our agent is actually working?
In this guide, I’ll walk you through the fundamentals of evaluating modern AI agents. You’ll learn why traditional software testing isn’t enough, what new techniques have emerged, and step-by-step evaluation practices to make your agents reliable, debuggable, and ready for production.
What Are AI Agents?
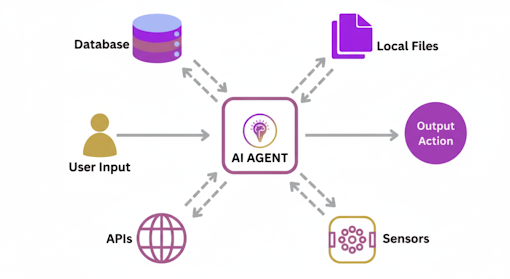
AI agents are smart software programs or helpers that can perceive their environment, reason about goals, take actions using external tools, and adapt their strategies over time. Unlike traditional software or static chatbots, modern agents are designed to think, plan, and interact across multiple steps, often handling tasks that require searching, summarizing, coding, or even embedding other services.
"AI agents are not just LLMs with prompts—they are decision-making entities that use perception, planning, and action to solve tasks over time."
— Lilian Weng, OpenAI Researcher
AI agents can act as your digital co-workers who can sense what’s happening, reason about what to do next, and then act to accomplish their objectives. Unlike simple chatbots, AI agents don’t just follow scripts. They take initiative, adapt to new information, and work toward outcomes.
How do AI Agents Work?
Imagine you want to automate research on a new market trend, then if you ask a regular chatbot to research, it can only answer simple questions using what it already knows. If you want a summary or up-to-date information, it can’t help much and ends up repeating what it’s learned before.
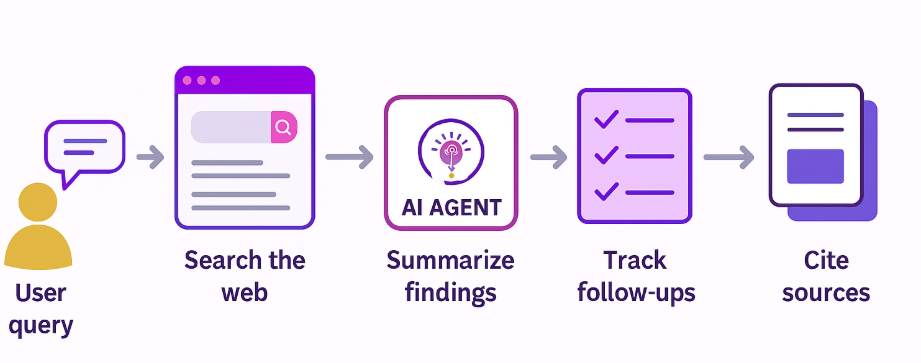
On the other hand, an AI agent like OpenAI’s Deep Research or Google’s Gemini Agent does much more. For the same research task, an AI agent can:
- Search the web for the latest articles, papers, and news
- Aggregate and summarize findings from multiple sources
- Track and incorporate any follow-up questions, building on previous context
- Cite sources directly for transparency and reliability
- Invoke external tools and APIs to retrieve up-to-date statistics
Unlike static systems, an AI agent plans a workflow, remembers what it’s already checked, adapts its strategy as new information arrives, and manages multiple steps to achieve its goal. This guide by Adaline Labs is an interesting resource to learn more about AI agents from scratch.
Key Characteristics of AI Agents
AI agents stand out from traditional software and chatbots due to several important features, including:
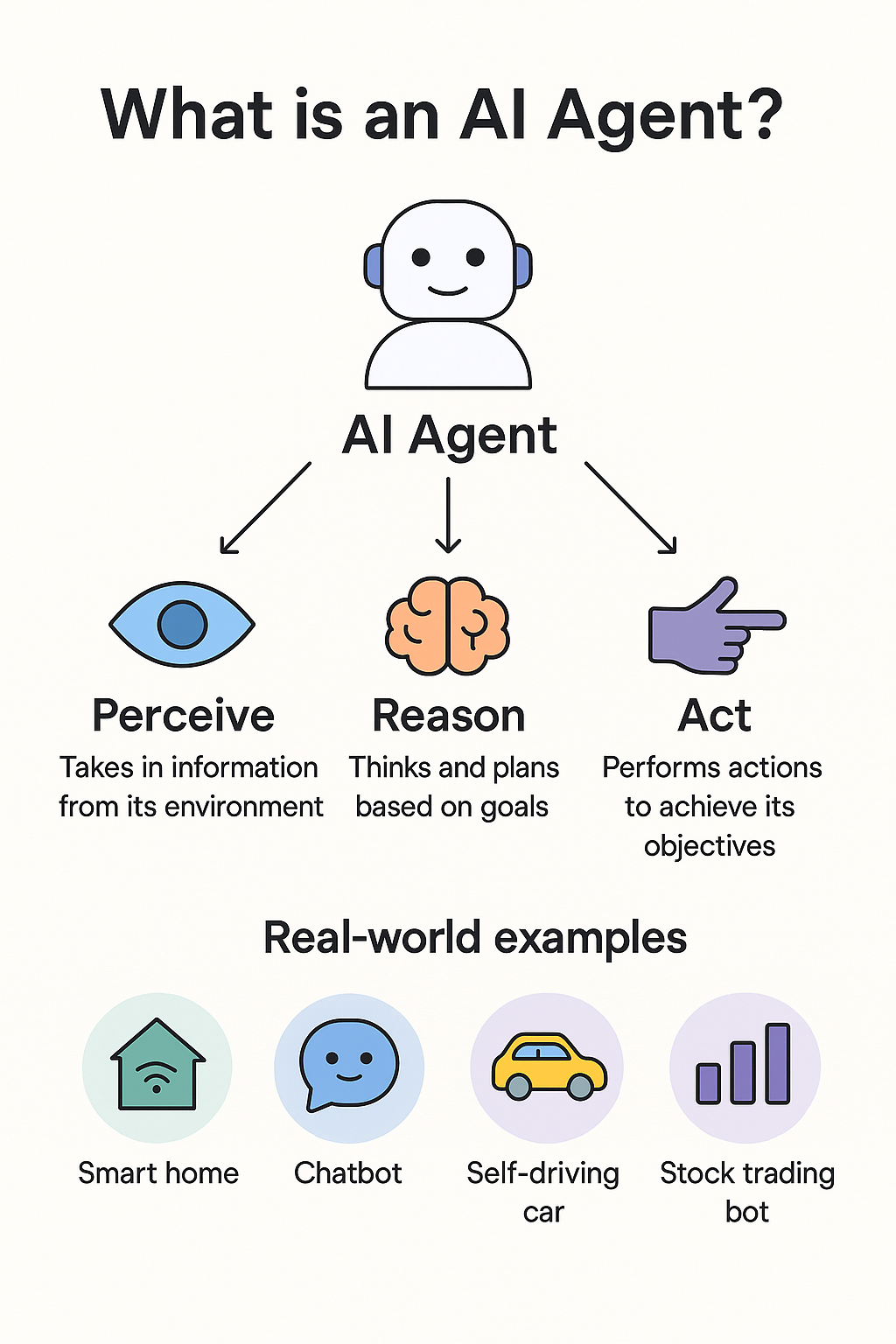
- Perception, reasoning, and action: AI agents stand out because they don’t just process information passively, but they actively interact with the world around them.
- First, they perceive their environment, whether that’s reading user inputs, monitoring sensor data, analyzing documents, or observing real-time events.
- Next, they reason about what this information means in the current context, drawing on logic, learning patterns, and goals to decide on the best course of action.
- Finally, they act by running commands, making decisions, triggering workflows/API’s/tools, and returning results.
- Autonomy and decision-making: Unlike simple automation scripts, AI agents operate independently, making decisions without step-by-step human supervision. For example, a self-driving car is an AI agent, i.e, it constantly scans its surroundings, predicts what other cars might do, and makes split-second decisions for the safety of the passengers, pedestrians, as well as the car.
- Learning and adaptability: The power of an AI agent is in its ability to learn from experience and adapt to new situations. For instance, AI coding assistants like GitHub Copilot adapt to users’ unique coding style by observing user edits and feedback.
- Continuous improvement: Modern AI agents are designed to optimize their actions over time. This might mean self-tuning for better performance, or adapting their strategies as environments or requirements change.
Why Evaluate AI Agents?
As these agents become an integral part of products, from research assistants to coding copilots, the cost of untested behaviors, errors, or unsafe actions grows exponentially. Unlike classic ML models, agents operate over long time horizons, make tool calls, and accumulate a lot of context and data.
Robust evaluation is essential to ensure agents are not only helpful and accurate but also safe, trustworthy, and cost-effective.
With growing automation, agents can now make decisions from booking travel to offering financial advice. This increases responsibility as well as risks, such as:
- Unpredictable errors: Agents may hallucinate facts, misuse APIs, or take unsafe actions.
- Context drift: Stateful agents can forget key information and propagate outdated context.
- Safety and compliance: Agents acting on the user’s behalf must adhere to organizational policies and legal regulations for AI ethics.
Comprehensive evaluation ensures that AI agents remain safe, and trustworthy as they make complex decisions. Without robust monitoring, errors and risks can quickly scale in production environments.
Evaluating Agents vs. Traditional Models
Traditional software testing expects the same output every time you give the same input. Tests are designed to verify that the results align with what’s expected. Even classic LLM evaluation typically involves a prompt-in, answer-out approach, which relies on checking factual correctness or a similarity check against ground truth.

Let's walk through a few ways AI agents fundamentally break these assumptions:
- Non-determinism: Modern agents, especially those powered by large language models, are stochastic. The same query may yield different outputs due to model sampling, randomness in tool selection, or evolving memory states.
- Multi-step and multi-session workflows: Agents operate across entire workflows, not just isolated inputs. Their performance depends on how they manage context, update memory, and chain decisions over time.
- Tool usage and external actions: Agents make real API calls, search the web, and trigger downstream automations, which means the environment itself can change between evaluations. The agents need to adhere to these changing requirements.
- Context and history awareness: Unlike stateless applications, agent behavior is shaped by changing context, such as prior messages, stored facts, retrieved docs, and conversation history.
- Safety and transparency: Since agents are trusted with autonomous actions, “correctness” is not enough. We must measure hallucination risk, tool misuse, ethical guardrails, and the ability to explain decisions as well.
Implications For Evaluation
Since AI agents operate differently from traditional models, evaluating them requires new approaches and metrics. Here’s what changes when assessing agentic systems:
- Not just pass/fail: Many agent tasks do not have a single “correct” answer. The quality may be judged on helpfulness, reliability, or process. For example, did the agent use the right tools, follow constraints, explain reasoning, and more.
- Process-level metrics: Evaluation must look beyond outcomes to “how” the agent reached them (like Did it recover from errors? Was its reasoning transparent? Did it maintain task state across turns?).
- Benchmarks: Agent benchmarks like BrowseComp, SWE-bench, and AgentBench not just track answer correctness, but also track multi-turn accuracy, tool usage efficiency, persistence on long tasks, and even user satisfaction.
Evaluating agents calls for frameworks and metrics that move well beyond simple input/output checks. We need to trace agent decision-making, combine automated and human judgment, track edge-case failures, and continuously test agents in real-world scenarios.
Key Metrics for AI Agents
Robust evaluation means tracking multiple dimensions of performance, and how the agent achieves its goals and delivers value to users. The core metrics that matter, includes:
- Task success rate: This metric measures how reliably the agent completes its assigned tasks, such as booking a flight or resolving a support ticket.
- Correctness and relevance: It assesses whether the agent’s responses are factually accurate and useful for the user’s objectives.
- Efficiency and step count: These metrics capture how efficiently the agent achieves its goals, minimizing unnecessary steps and avoiding repeated loops.
- Faithfulness: It ensures the agent’s outputs are grounded in the tools and data it accessed, with accurate references and citations.
- User experience: It reflects the quality of interaction, such as natural conversations without repetitive questions.
- Cost and latency: Both of these metrics track the agent’s resource usage, including tokens, API calls, and response time, to ensure fast and cost-effective operation.
Together, these metrics provide a 360-degree view of agent performance by balancing accuracy, efficiency, user experience, and real-world feasibility.
Step-by-Step: How to Evaluate AI Agents in Practice
Evaluating modern AI agents goes far beyond simple accuracy scores. You need structured, end-to-end processes that capture reasoning, adaptability, and safety.
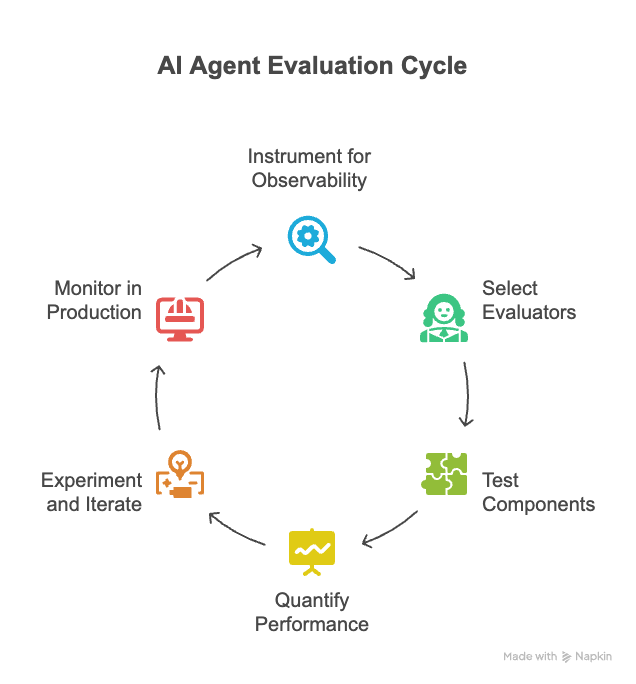
The following framework can help you evaluate AI agents effectively:
1. Instrument for Observability
Before you can improve or debug an agent, you need to see exactly what it’s doing. By logging every action and visualizing traces, you can pinpoint where things go right or wrong across complex workflows. For this, we need to:
- Log every step: Track all actions, tool/API calls, decisions, and messages.
- Visualize traces: We can make use of open-source tools like Arize AI, LangSmith, WandB, and more to spot bottlenecks and failure points in agent workflows.
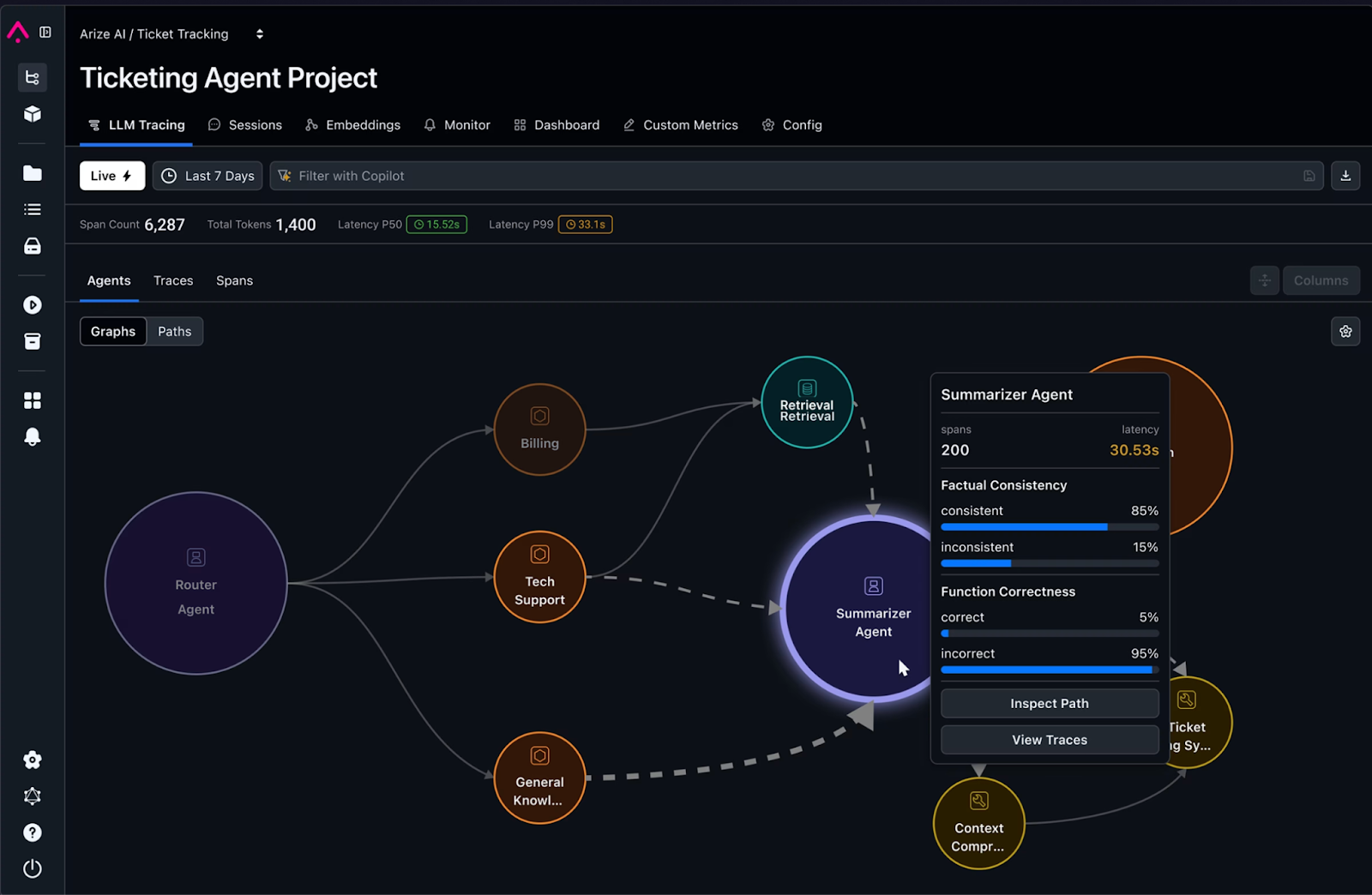
Source: Arize AI
2. Select the Right Evaluators
Choosing the right evaluator is essential when testing AI agents. For example, using automated tests for tasks with fixed answers or relying on LLMs or human reviewers for open-ended responses. The right evaluator depends on the component you’re testing.
- Code-based tests: For deterministic components such as calculators, structured API integrations, and database queries, traditional automated tests are well-suited. These tests help to validate the input-output relationships, ensuring that for a given input, the component consistently produces the expected output.
- LLM-as-a-judge: We rely on LLMs as a judge for grading open-ended answers, checking relevance, and reasoning. This technique can assess factors like relevance, factuality, helpfulness, and logical coherence, either by following a scoring rubric or answering “meta-prompts.” It is also helpful for evaluating nuanced responses and multi-turn outputs where classic pass/fail tests are insufficient.
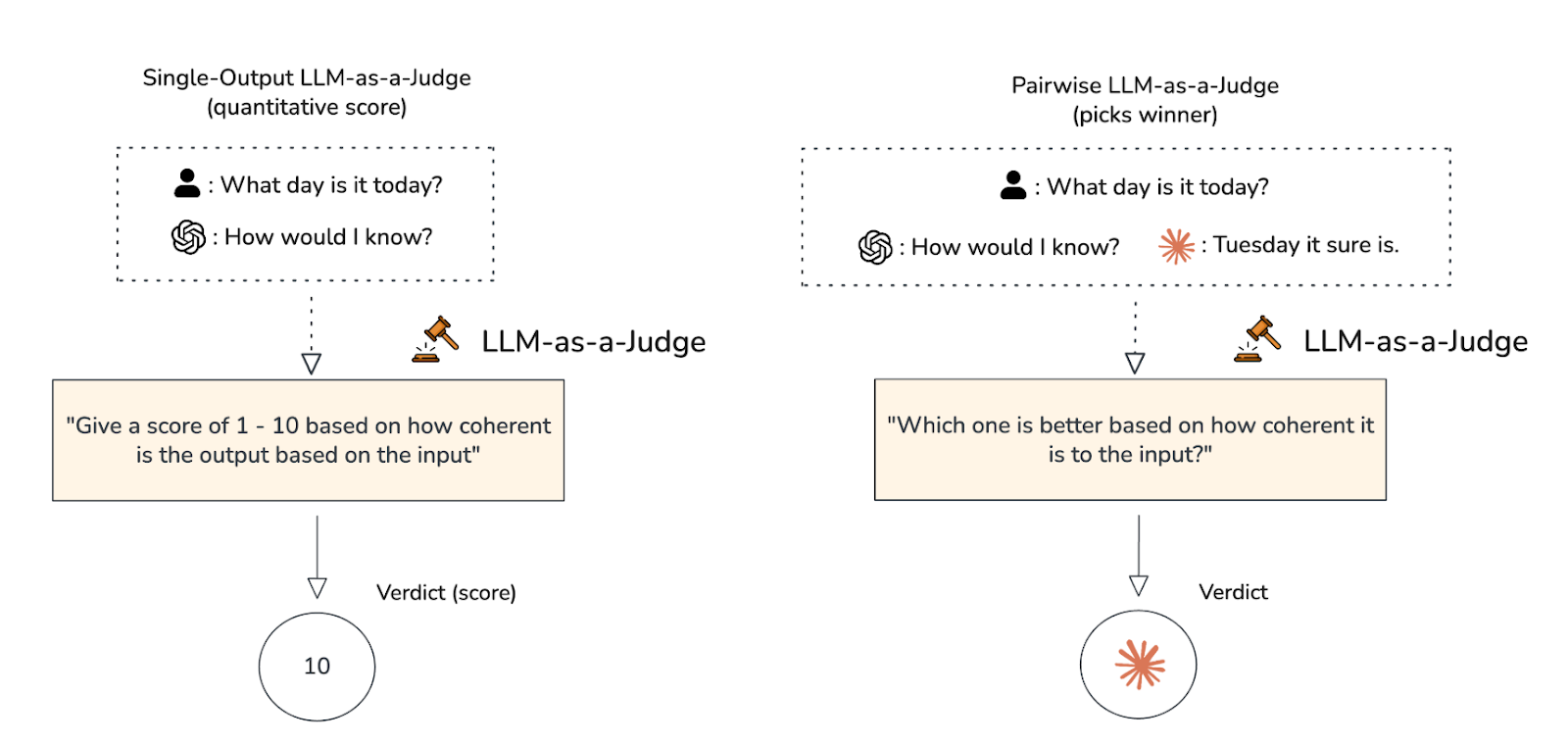
Source: Confident AI
- Human review: For high-stakes, ethical, and safety-critical tasks, human judgment remains essential. Human-in-the-loop evaluation is particularly important for scenarios where the agent might cause harm, exhibit bias, or violate compliance. Human reviewers are also key to setting standards that can later be used to calibrate LLM-based judges.
3. Component and End-to-End Testing
Once you choose the right evaluator/s for your AI agents, isolate and validate individual skills, then check how multi-step workflows capture both edge cases and standard user journeys. For this step, we:
- Curate test cases: We start by collecting realistic and edge-case scenarios from actual agent traces.
- Evaluate skills: Then, we test each agent’s ability to search, plan, code, and summarize using both code and LLM-based judges.
- Assess routing: Finally, we check if the agent correctly selects tools or sub-tasks at each decision point.
4. Quantify Performance and Efficiency
Efficiency matters as much as accuracy. So, we count the number of steps, monitor costs, and track different errors to see if our agent reliably completes tasks without confusion. In this step, we check for two key parameters:
- Convergence score: The convergence score measures whether an agent achieves the desired task outcome within an acceptable and efficient number of steps.
- Comprehensive metrics: A robust evaluation framework must track a wide range of metrics like latency, tool usage cost, error rates, efficiency, etc, enabling us to diagnose inefficiencies, cost overruns, and performance regressions.
5. Experiment and Iterate
Once we have all the required metrics and parameters in place. Next, we continuously test new ideas with A/B experiments and regressions, where failures are often used as feedback to refine prompts, logic, and skills. These are some standard experiments we use to evaluate AI agents:
- A/B tests: We test new prompts, models, and logic side by side with the current version. This lets us objectively compare which approach yields better results for specific tasks.
- Regression testing: We re-run a set of previously successful cases every time we update our agent. This ensures that improvements don’t accidentally break existing capabilities or introduce new bugs.
- Feedback loops: Finally, we analyze failures of each agent to identify where the agent went wrong, then use those insights to refine prompts, adjust logic, or train new skills, thereby creating a continuous improvement cycle.
6. Monitor in Production
After experiments are conducted, we use dashboards to monitor agent behavior in real time, set up automated guardrails for risky outputs, and roll out updates to catch issues early and protect users.
- Continuous dashboards: We observe agent behavior and metrics in live traffic using interactive dashboards.
- Guardrails and alerts: We also set up automatic alerts for risky or unexpected behavior and escalate to experts when needed.
- Safe rollout: It is the best strategy to release changes to small user groups first, then monitor and scale up as required.
Pro Tip: Use open-source platforms like Arize AI, LangSmith, or Promptfoo to automate trace collection, LLM-based evaluation, and regression testing for your agent pipelines.
Common Agent Evaluation Challenges
Evaluating AI agents in practice comes with unique challenges that go beyond standard software testing. Some of the most common challenges to be aware of are:
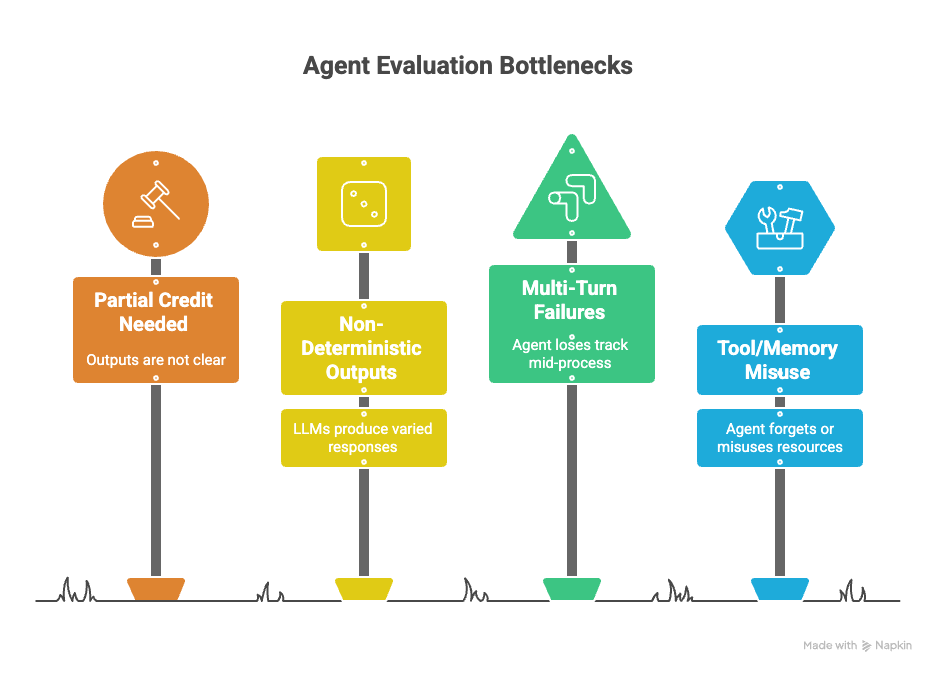
1. Grading answers: Not every agent response fits neatly into “correct” or “incorrect.” Many outputs are “partially correct” or require some form of grading. LLM-based graders or human reviewers are often used to score responses along a quality spectrum instead of just pass/fail.
2. Handling non-determinism: LLMs can produce different outputs for the same input due to their probabilistic nature. This makes traditional one-run testing unreliable. Thus, running evaluations multiple times helps achieve more stable results.
3. Debugging multi-turn interactions: Agents often succeed in early steps, then hallucinate or make mistakes in longer conversations. Capturing detailed logs and step-by-step traces is critical for identifying where and why breakdowns occur across multi-turn workflows.
4. Testing tool and memory usage: Agents may misuse tools, forget prior context, or act on outdated information as well. Thus, creating targeted tests that check memory recall, proper tool selection, and the ability to recover from missing or wrong information can help mitigate this challenge.
Conclusion
AI agents in 2025 are more capable than ever, but only as reliable as your evaluation framework. Building robust, observable, and well-tested agent workflows is the difference between demos and real-world adoption.
Agent evaluation is a core skill for product builders who want to ship agentic systems that truly work. With the right evaluation tools and techniques, you can move from demos to production-level AI systems quickly and efficiently.
Want to become an AI engineer?
Learn the skills that matter on our hands-on Software & AI Engineering programme.