
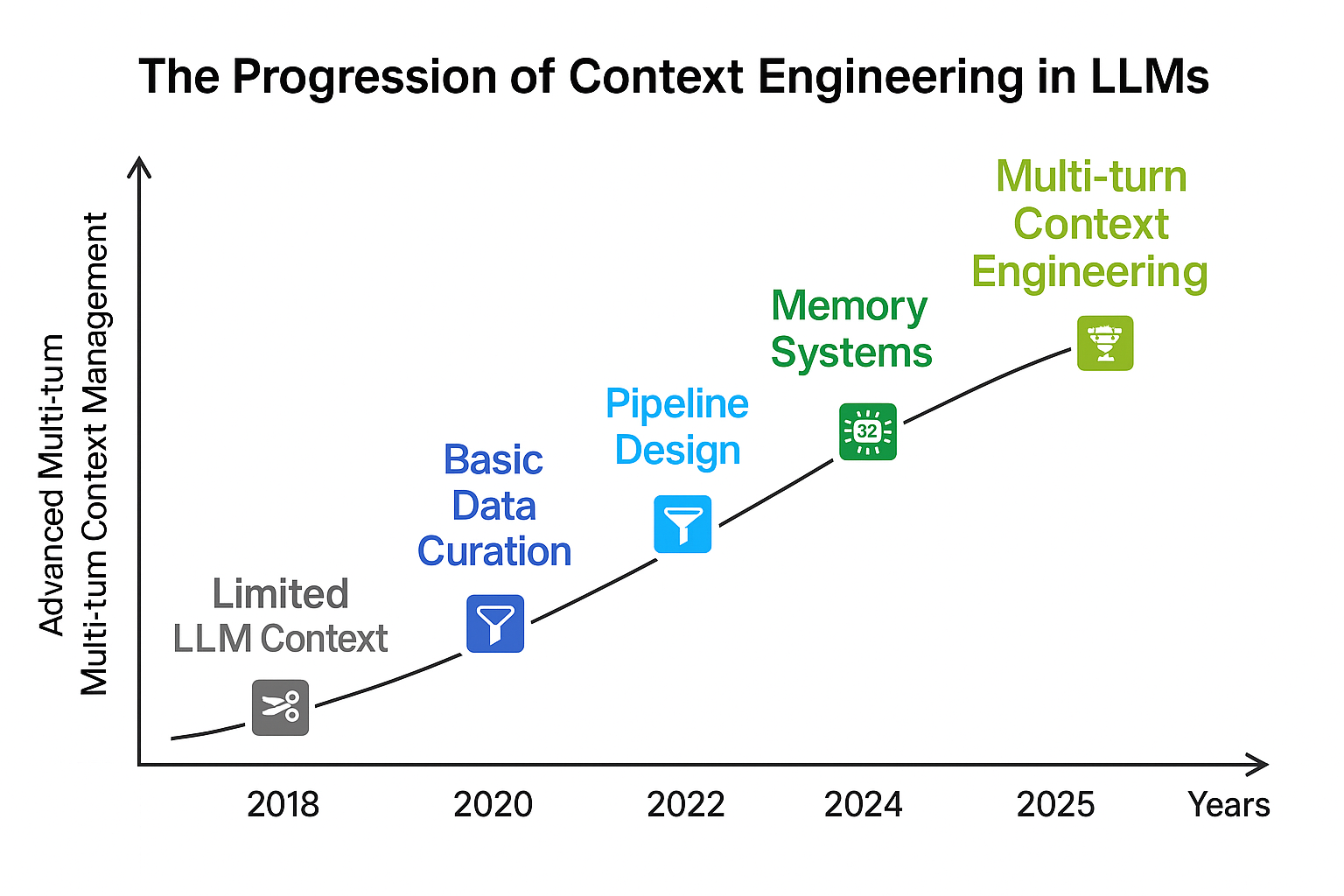
The era of prompt engineering is fading, and in 2025, AI is expected to do much more than answer questions. While large language models (LLMs) have become dramatically more powerful in recent years, their ability to handle and remember all the information needed for complex tasks is still limited by the size of their context window. We have become more prompt-efficient, yet models are still struggling to manage large amounts of information, optimize their context window, and synthesize extra information on the fly.
So, what has actually changed for serious AI builders this year? The shift is clear, since we have moved past just crafting better prompts and are now focused on designing the entire flow of information. This means making sure your model not only hears what you say but also truly understands and remembers what is important.
If you have ever been frustrated by LLMs that forget crucial details or lose track after a few turns, this guide will help you build context-aware AI that remembers what matters, from the very start of your conversation.
What Is Context Engineering?
Context engineering involves designing an architecture that determines how information is selected, formatted, and delivered to the model at runtime. It means going beyond single-shot instructions to building pipelines and memory systems that dynamically curate and assemble data from multiple sources.
Imagine using a language model that only remembers your last sentence. This is the default behavior of most LLMs, since they are stateless beyond their immediate input. As LLM applications grow in complexity, simply making prompts longer is not enough. Once the volume and variety of context expand, prompt engineering quickly hits its ceiling. At this point, context engineering becomes essential, especially for real-world applications that demand accuracy, memory, and multi-turn reasoning.
Context engineering brings together everything the model might need, i.e., system instructions and behavioral rules, conversation history, user preferences, live API data, documents and knowledge bases, tool definitions, and even formatting guidelines. To put this into perspective, Andrej Karpathy describes it simply:
"The LLM is the CPU, and the context window is the RAM."
In this analogy, context engineering acts like the operating system, deciding what data to load into memory and when, ensuring the model always has the information it needs.
But does this mean prompt engineering is no longer necessary? Not at all. Prompt engineering is all about crafting a single, effective instruction for the model, while context engineering involves architecting the entire information ecosystem that surrounds and supports that prompt.
Context Engineering vs. Prompt Engineering
Prompt engineering is fundamentally about optimizing the words and structure of a single instruction to get the desired response from a language model. While this skill is valuable for simple tasks, it quickly hits its limits as the LLM applications start to require reasoning over richer, multi-source data.
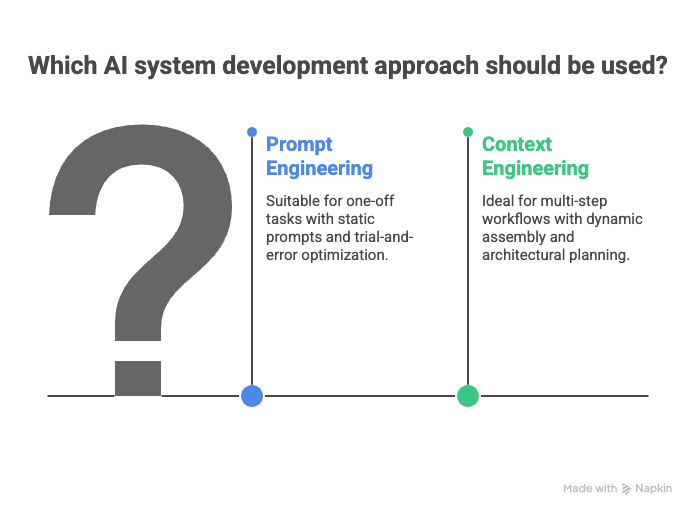
Context engineering takes things further, i.e, instead of relying solely on prompts, we design systems that assemble and format context from a variety of sources such as conversation history, retrieved documents, user preferences, and tool outputs. The model receives a complete, well-structured input package as a part of its context that allows it to handle multi-step workflows and memory for ever-increasing user needs.
A Practical Example
To see the difference in action, let’s consider a travel booking assistant.
Prompt Engineering Example: A user provides a complete one-shot instruction to the model as follows:
Prompt: “Book a flight from SF to Tokyo on Aug 20. Add baggage & refund info.”
Here, all the information, such as destination, date, and requested options, must be explicitly included in each prompt. The model has no memory of the user's preferences or prior conversations.
Context Engineering Example: Now imagine a system that dynamically assembles context from various sources before the model generates a response:
- System: "Travel assistant."
- User Preferences: Prefers window seats and vegetarian meals.
- History: Previously asked about Tokyo hotels and flexible tickets.
- Live Data: Current flight options for September 20.
- Policies: Always mention baggage allowance and refundability.
With context engineering, the assistant remembers the user’s preferences, past queries, and relevant company policies.
Why Context Engineering Matter More
When agentic LLM systems fail, it is often not because the underlying model is incapable, but because the model was not passed the context required to make a good decision. This can be due to missing facts, poor formatting, or a lack of tool access. As LLMs become stronger, context engineering becomes even more important, since most failures shift from model-level mistakes to context-level mistakes.
Shopify's CEO Tobi Lütke has noted:
“I really like the term ‘context engineering’ over prompt engineering, it describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.”
Prompt engineering focuses on crafting the optimal structure of a single instruction. However, as applications become more dynamic and complex, simply rewording the prompt cannot address all challenges. Context engineering subsumes prompt engineering, since you are not just architecting a prompt for static data, but constructing a context from diverse sources and embedding it into the model’s input at runtime.
A crucial part of context is still core instructions for how the LLM should behave. These instructions, which are typically set in system prompts that are an intersection of both. So, you need both clear, robust instructions and a system for delivering all supporting information most effectively. Thus, prompt and context engineering go hand in hand.
How Context Engineering Actually Works
Context engineering powers LLM applications by managing data, memory, and tools for reliable performance. This is best seen through Retrieval-Augmented Generation (RAG), dynamic agents, and coding assistants.
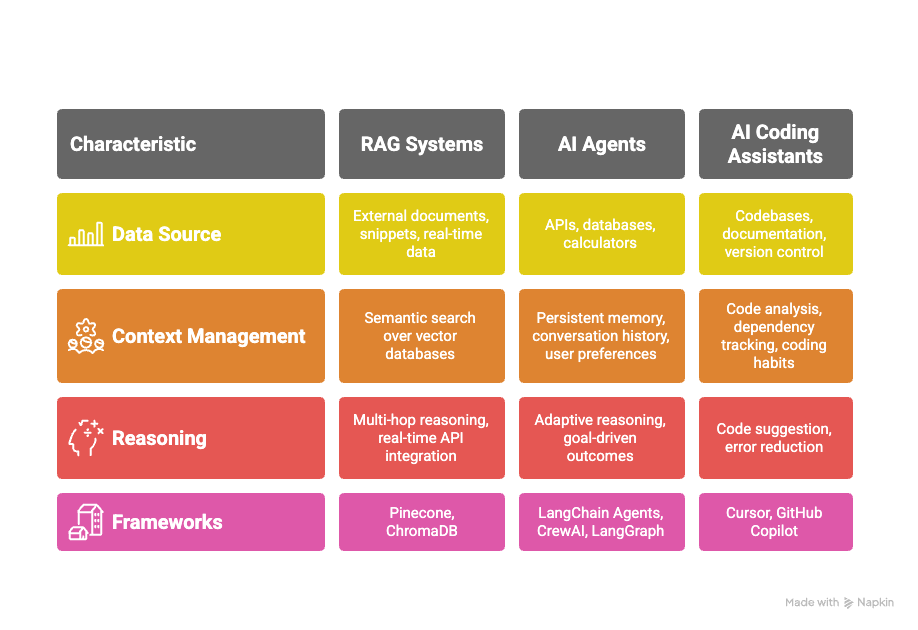
1. Retrieval-Augmented Generation (RAG) Systems
Retrieval-augmented generation (RAG) is a technique that combines large language models with external retrieval systems, enabling the model to access relevant data or documents at inference time instead of relying only on what it was trained on. This means you don’t have to fine-tune your model on every new dataset; instead, you can fetch up-to-date information for each request. Here are some key points about RAG:
- RAG uses semantic search and vector databases like Pinecone and ChromaDB to break down and rank chunks of information for every prompt.
- This design supports complex workflows like multi-hop reasoning across sources and injecting real-time data through API calls.
- With RAG, LLMs can answer domain-specific or rapidly evolving queries far more effectively than models relying only on static training.
2. AI Agents
Agent-based LLM systems are where context engineering gets even more dynamic. Here, AI agents can combine persistent memory, tool use, and adaptive reasoning to manage workflows that span multiple turns with users.
- Using frameworks like LangChain Agents or CrewAI, these agents can autonomously pick and use APIs, databases, or external calculators that help in updating context after every interaction.
- AI Agents don’t just store history, but they actively track workflow progress, user preferences, and ongoing conversation state to deliver relevant outcomes.
- The introduction of orchestrators such as LangGraph allows for teams of specialized sub-agents to share, update, and build on context for advanced task automation and collaborative reasoning.
3. AI Coding Assistants
Modern coding copilots are the best real-world proof of context engineering at scale. Tools like Cursor and GitHub Copilot analyze entire codebases, mapping out dependencies, project structure, and code relationships to tailor responses to your workflow. Here is how they do that:
- These assistants curate context from snippets, documentation, and version control logs, letting the LLM reason about both immediate edits and the overall architecture.
- By observing your unique coding habits and recent changes, coding copilots can adapt suggestions for higher accuracy and fewer errors.
- In large organizations, this approach is a game-changer and may result in a 26% increase in completed software tasks and a measurable drop in code errors when teams use context-aware coding assistants
Context engineering is now a core skill, and you can learn more concepts around this topic in top AI engineering programs.
Common Context Failures
Even with state-of-the-art models, your application can fail spectacularly if context is not engineered with care. Understanding these failure modes is essential for anyone building LLM-powered systems. Here are four classic failure patterns that are important for engineers to address:
1. Context poisoning: Context poisoning occurs when incorrect, hallucinated, or outdated information makes its way into the model’s context window and is then repeatedly referenced in subsequent outputs. This can result in the propagation of errors, persistent hallucinations, or even the adoption of “false beliefs” by the agent over the course of a workflow. DeepMind’s research on game-playing agents highlighted this risk, where a hallucinated game state contaminated the agent’s memory, derailing performance for many turns.
Mitigation strategies include implementing strong validation checks before allowing information into memory, thereby isolating unverified data in a temporary “quarantine” buffer, and applying consensus or majority-vote approaches across multiple evidence sources.
2. Context distraction: When the context window becomes too large, models may “anchor” on the accumulated history and lose their ability to generalize on what is actually relevant. Databricks research shows that, even for top-tier models like Llama 3.1 405b, accuracy dips beyond 32,000 tokens. This is long before the theoretical maximum context size is reached, showing that bigger context windows alone are not enough.
Best practices for avoiding context distraction involve periodically summarizing or compressing conversation history, outdated details, and prioritizing recent context through scoring mechanisms or relevance models.
3. Context confusion: Context confusion arises when the model is presented with too much irrelevant data, such as extraneous documents, poorly selected tools, or irrelevant user information. Berkeley's function-calling leaderboard demonstrates that model accuracy often drops when more than one tool or too much non-essential context is presented, even if the context window is not full.
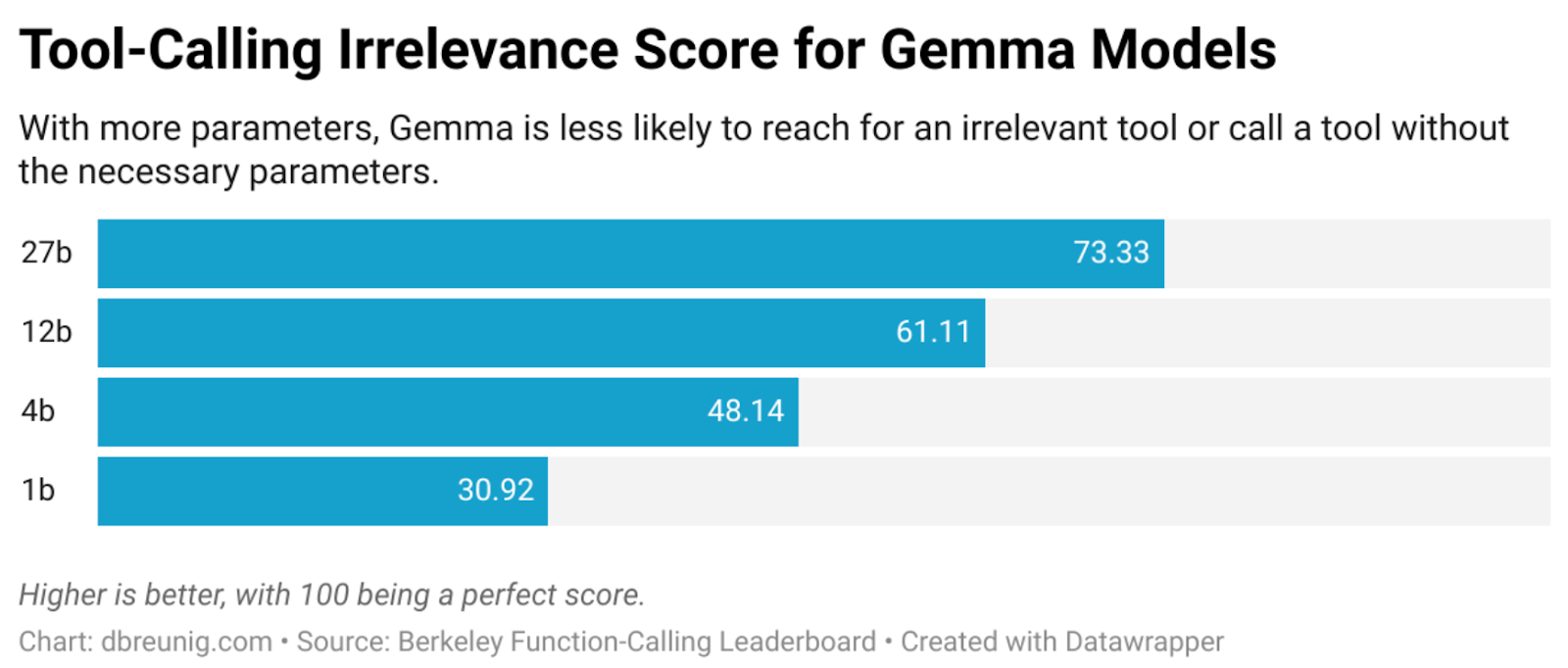
Effective context engineering here relies on retrieval-augmented techniques like using vector search, RAG, or other filtering methods to inject only the most relevant facts, tools for the current task, rather than looking for complete information.
4. Context clash: A context clash happens when contradictory or duplicate information is included in the input, causing logical inconsistency in reasoning. Multi-turn conversational flows, especially with partial or staged updates, are particularly vulnerable. A Microsoft and Salesforce research study found that fragmented contexts provided over several turns led to a dramatic 39% drop in LLM performance.
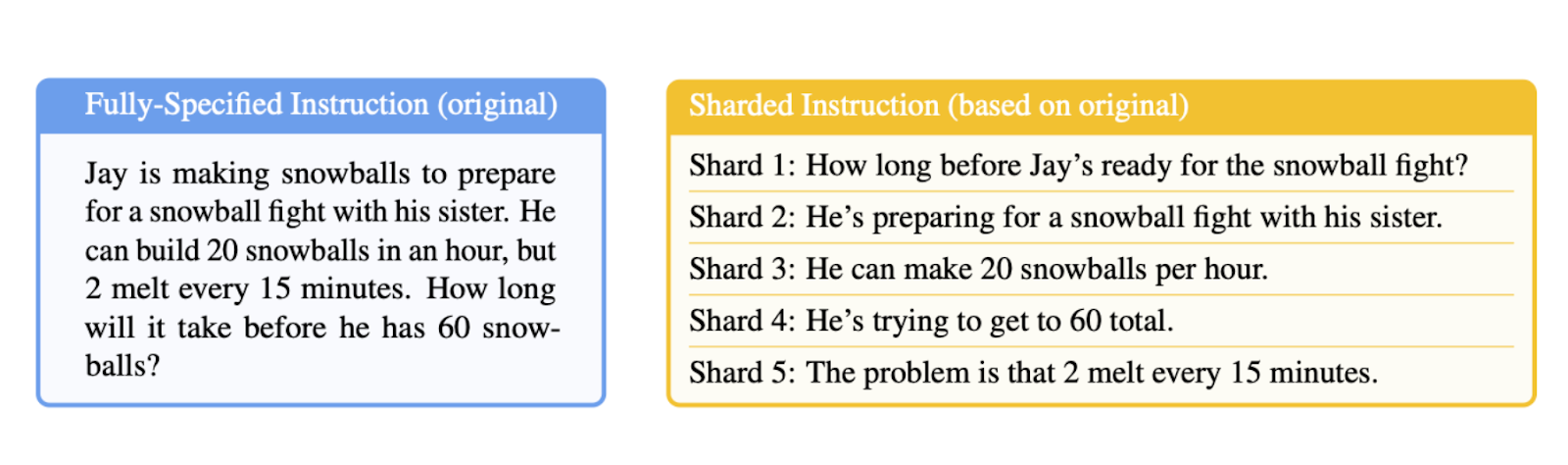
Remediation involves actively pruning outdated or conflicting information, using separate reasoning threads, and applying conflict-resolution logic before passing context to the model.
Conclusion
Context engineering isn't just another AI buzzword. It's the fundamental skill that separates experimental demos from production-grade systems. Context engineering will continue to grow in importance as AI systems become increasingly complex. While models are increasingly efficient at handling complex contexts, output quality still depends on the delivery of context. The upcoming breakthroughs in context engineering will focus on:
- Advanced memory systems for persistent and long-term context
- Integrating multi-modal context like text, images, and structured data
- Automated context optimization using AI to refine context assembly
- Tools to measure, debug, and monitor context quality at scale
Want to become an AI engineer?
Learn the skills that matter on our hands-on Software & AI Engineering programme.