
We asked both models to build the same thing: a browser-based snake game with score tracking and collision detection. Codex 5.3 ground through it in 6 minutes — methodical, correct, every edge case handled on the first pass. Spark spit out a working version in 50 seconds. The game ran, the snake moved, the score incremented. But the collision logic had a one-pixel blind spot on the left wall, and the restart function leaked memory.
That 5-minute-and-10-second gap is the entire Codex 5.3 vs. Codex Spark debate, compressed into one test.
What Is GPT-5.3-Codex-Spark, and Why Should Senior Engineers Care?
GPT-5.3-Codex-Spark is a distilled, Cerebras-accelerated variant of OpenAI's Codex 5.3, purpose-built for low-latency code generation at 1,000+ tokens per second with a 128k context window. Available as a research preview for ChatGPT Pro subscribers, it is not a replacement for Codex 5.3 — it is a stripped-down sibling optimized for throughput over reasoning depth.
"Distilled" means OpenAI compressed the full model's knowledge into a smaller architecture that Cerebras' Wafer Scale Engine 3 can push at blistering speed. Think of it like JPEG compression for neural weights: the broad strokes survive, but fine-grained detail bleeds out.
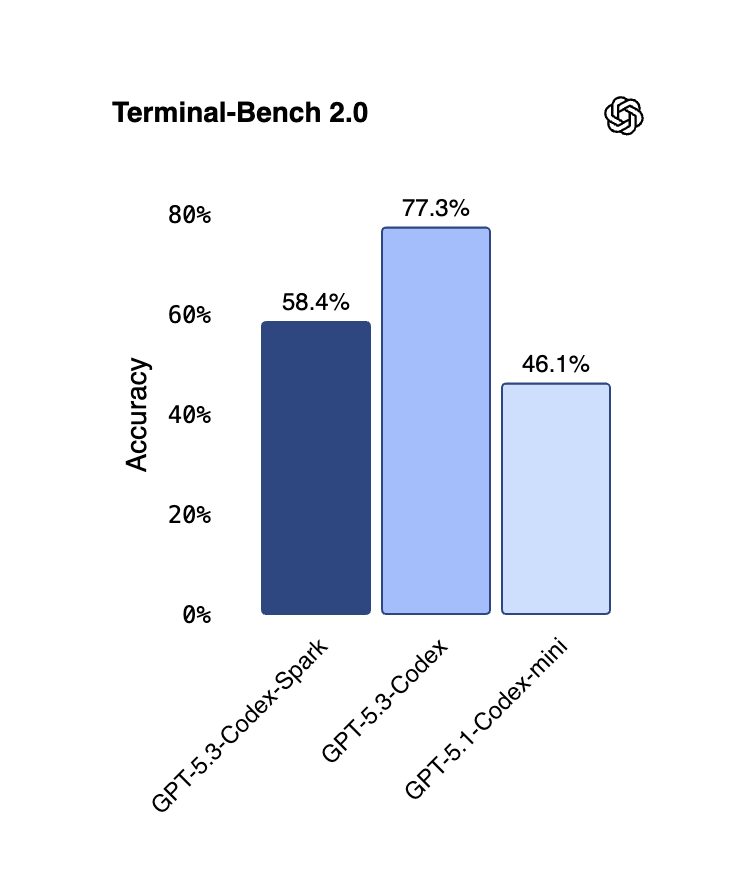
Where Does Codex Spark Beat Codex 5.3 — And Where Does It Faceplant?
Spark dominates tasks that are small, self-contained, and tolerant of minor errors. It collapses on multi-step reasoning, stateful workflows, and complex debugging.
Codex Spark's Sweet Spot
- Rapid prototyping. One X user built a full SpriteKit game in 20 minutes, calling Spark "INSANELY FAST." For workflows that demand 30 drafts of a component in the time it takes to drink a coffee, Spark delivers.
- Single-file edits. Swap a function signature, rename variables across a module, generate a utility — Spark returns results before the thought fully forms.
- Frontend iteration. CSS tweaks, React component adjustments, layout experiments. Multiple developers on X described responses arriving "before you finish reading your own prompt."
Where It Breaks
- Multi-step planning. Spark dropped critical constraints after 6–8 steps in our sequential chain tests.
- Complex debugging. When the bug spans three services, Spark patches the symptom and ignores the root cause.
- Structured output. Multiple X threads flagged unreliable tool-call formatting — JSON schemas missing fields, function signatures with phantom parameters.
- Long context. The 128k window falls short for large codebase analysis; the full Codex 5.3 handles 400k+.
Codex 5.3 vs. Codex Spark: Full Comparison
That last row should keep senior engineers awake. A slow model is annoying. A fast model that ships plausible-looking bugs is dangerous.
What Do Developer Reactions on X Reveal About the Speed-vs-Depth Trade-off?
Reactions split into two camps within hours: speed evangelists who called Spark "revolutionary" and experienced engineers who warned the 16-point SWE-Bench Pro drop makes it unreliable for production work.
The Speed Camp
The official OpenAI and Cerebras announcements set the tone. TechCrunch and VentureBeat amplified the hype on launch day. Frontend developers and indie hackers gravitated toward Spark because their workflows already consist of small, self-contained edits — the exact pattern it handles well.
The Skeptics
AI developer Zeb Anderson posted one of the sharpest breakdowns on X after a full day of testing. His core observation: Codex 5.3 "behaves like a disciplined senior engineer working through a checklist," while Spark "feels like AGI in terms of speed and work output" but "needs tighter steering for structured, exhaustive workflows."
Manish Kulariya delivered the bluntest take in an X post that circulated for two days. Kulariya cited the SWE-Bench Pro gap and concluded OpenAI "traded brains for speed" — they didn't build a faster smart model; they built a less capable fast one.
Other recurring complaints:
- Hallucinations on routine tasks. Fabricated API endpoints, phantom package names, invented function parameters.
- Unreliable tool calls. Structured output formatting broke where Codex 5.3 handled it clean.
- Context drift. Developers loading large codebases reported Spark losing coherence toward the window's end.
BridgeMind captured the consensus: "Speed without intelligence is just fast failure." Not a dismissal — a boundary definition.
How to Deploy Codex Spark and Codex 5.3 as a Two-Model Workflow Tomorrow
Route small, verifiable tasks to Spark for sub-second iteration. Route complex or high-stakes tasks to Codex 5.3. This captures Spark's speed without absorbing its accuracy penalty.
Step 1: Classify Before You Prompt
One question: "Can this task be verified in under 30 seconds?"
- Yes → Spark. Utility functions, test scaffolds, component tweaks.
- No → Codex 5.3 (or Claude Opus). Architecture decisions, multi-file refactors, opaque debugging sessions.
Step 2: Spark Drafts, Codex 5.3 Reviews
Treat every Spark output as a draft. Scan for hallucinated imports, phantom parameters, and dropped edge cases — 10–15 seconds per function. If it passes, ship it. If not, feed the problem into Codex 5.3.
Our snake game test proves the math. Spark's 50-second draft gave us 90% of the game. We fed the collision bug and memory leak into Codex 5.3 with a two-line description. The full model patched both in 40 seconds. Total: under 2 minutes for a correct game vs. 6 minutes with Codex 5.3 alone. 3x faster, zero correctness sacrifice.
This drafter-reviewer pattern extends beyond games. Use Spark to write, Codex 5.3 to review. Prompt the reviewer: "Check this for correctness, edge cases, and security issues. It was generated by a fast model." Combined latency still ran 3–4x faster than using the full model for both steps in our tests.
Step 3: Hard Boundaries
Some tasks should never touch Spark:
- Security-critical code. Auth, encryption, input validation. A ~56% complex-task success rate is unacceptable here.
- Database migrations. One hallucinated column name corrupts production data.
- Multi-service orchestration. Three or more services = Spark's context drift becomes a liability.
Analysis reflects data available February 14, 2026. Spark remains in research preview; capabilities may shift.