Building A RAG Agent for Research Paper Analysis with CrewAI
17 min · October 13, 2025

Imagine asking an AI about a research paper and getting an answer backed by real citations, not guesswork. That’s the power of retrieval-augmented generation (RAG). From academic research tools to business copilots, RAG pipelines are now relied upon wherever accurate, evidence-based responses matter. In this hands-on guide, you’ll learn how to build your own research paper analyst using CrewAI, an open-source framework for agentic workflows.
This tutorial will guide you through the process of:
- Creating a RAG agent that analyzes academic PDFs and answers questions
- How CrewAI structures agents, tasks, and pipelines for easy composition
- Extending your project from a single-agent setup to a multi-agent workflow
At the end, you’ll have a working Streamlit app that lets users upload a research paper and interactively query it with sourced responses.
What is a RAG Agent?
A RAG agent combines the strengths of two AI components:
- Retriever: It finds relevant documents or passages to support a user’s query
- Generator: A generator synthesizes answers based on those retrieved sources and grounds every response in real evidence
This architecture helps ensure that answers are not only accurate but also supported by direct citations, minimizing hallucinations and making the results trustworthy for real-world tasks.
Here is an example of a RAG agent:
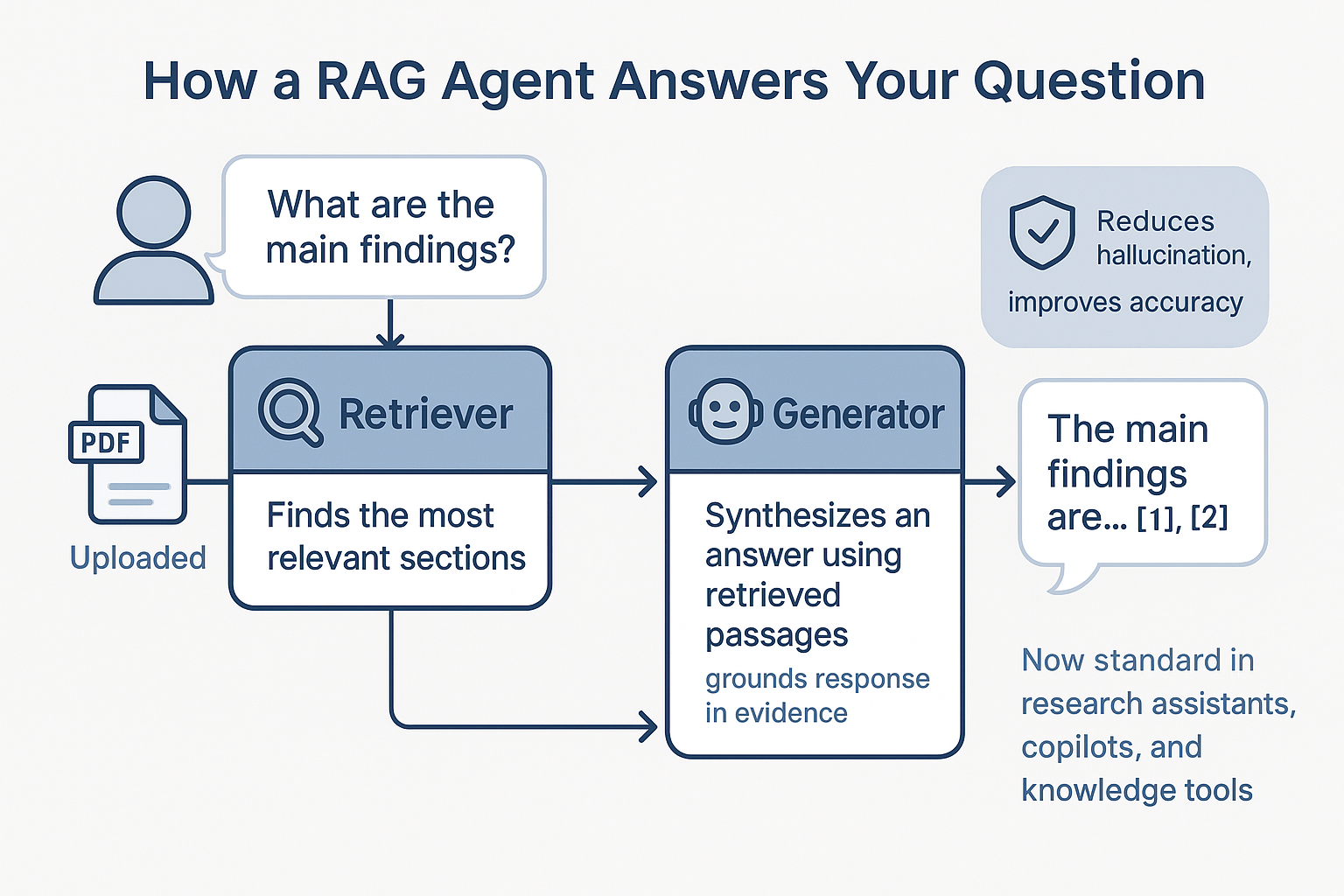
The user uploads a research paper, asking “What are the main findings?”, and the RAG agent will:
- Retrieve the most relevant sections
- Synthesize a summary using those passages
- Cite each key point, so the user can trace every answer back to its source
What is CrewAI?
CrewAI is an open-source framework purpose-built for orchestrating agent-based applications like advanced RAG workflows. It removes most of the repetitive setup work needed for multi-agent apps. That means you can focus on building clear, reliable workflows instead of wiring everything together yourself.
Key features include:
- Composable agents: You can build specialized agents for each job and combine them as needed, without requiring large and complex codebases.
- Built-in memory and context: Agents can remember previous steps and share information, which is essential for multi-step tasks and conversations.
- Tool integration: CrewAI connects directly to vector databases, APIs, and other tools.
- Built-in observability and guardrails: The framework tracks each agent’s actions and task flow for built-in tracing, metrics, and error monitoring.
- Multi-agent collaboration: You can start with a single agent and add more as your workflow expands. Swap out or add agent roles without breaking your pipeline.
- Beginner-friendly API: CrewAI is easy to set up and test. The API reference, quickstart documentation, and active forum can help you build and deploy quickly.
CrewAI is especially effective for RAG use cases, where coordination between retrieval, reasoning, and generation is critical:
- It helps in building workflows where retrievers fetch evidence, LLMs synthesize answers, and additional agents can verify facts, format citations, or escalate to human-in-the-loop.
- Crew AI also helps you extend your workflow as your needs grow. It allows us to add new agent types or split complex reasoning steps into dedicated tasks within a clean and maintainable architecture.
Demo Project: RAG Agent with CrewAI
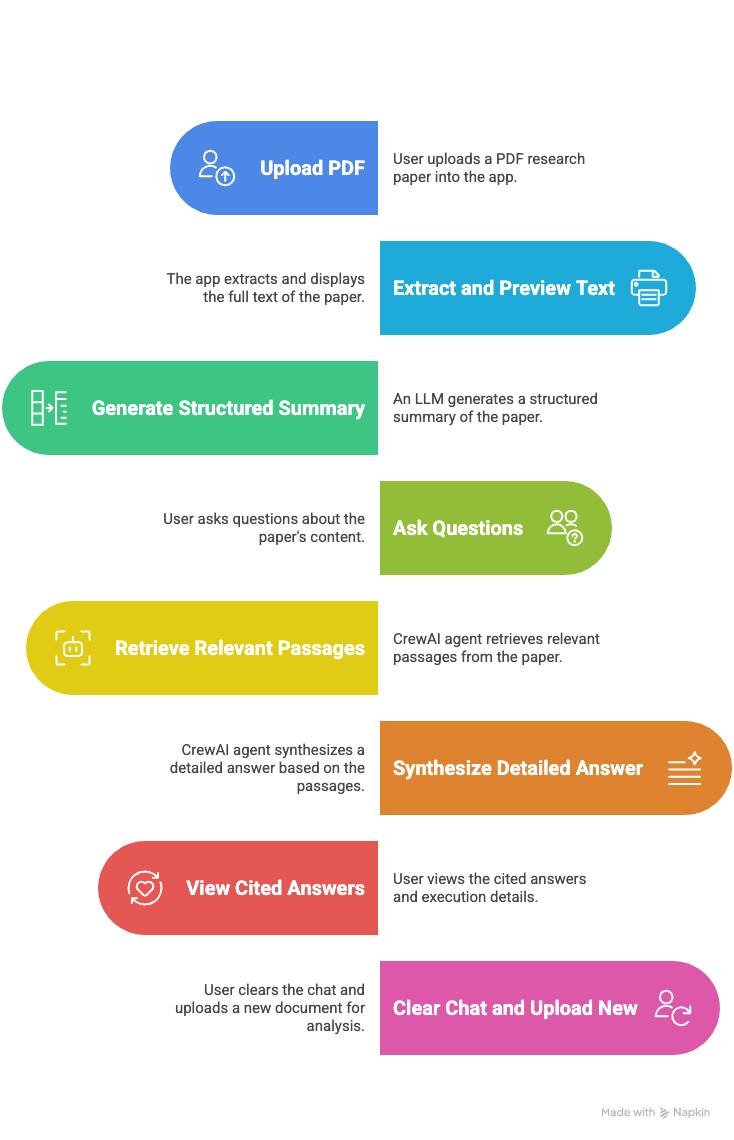
In this section, we’ll show you how to build a fully interactive research paper analyst using CrewAI and Streamlit. Here’s how the workflow unfolds:
Step 1: Set up the Environment and Libraries
Before we dive into building the Research Paper Analyst, let’s make sure the code environment and dependencies are in place.
```bash
pip install streamlit crewai langchain_openai langchain_community PyPDF2
```
The above command provides everything we need for document analysis, retrieval, agent orchestration, and a Streamlit interface. These dependencies cover all the critical components like Streamlit for web UI, CrewAI for building RAG pipeline, LangChain for vector stores, embedding models, and LLM access, and PyPDF2 library for PDF text extraction from the research papers.
Next, we set our OpenAI API key and import the core libraries needed for the project as follows:
```python
import os
import streamlit as st
import tempfile
import PyPDF2
import shutil
from io import BytesIO
from crewai import Agent, Crew, Task
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain_community.vectorstores import Chroma, FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
os.environ["OPENAI_API_KEY"] = "sk-proj-..." # Set your OpenAI API key
st.set_page_config(
page_title="Research Paper Analyst",
layout="wide",
initial_sidebar_state="expanded"
)
```
The code above helps in:
- API key setup: You can configure the OpenAI API key as an environment variable or directly use it in your code (for demo purposes only) to ensure access to LLMs and embeddings, which power both retrieval and generation in the agent pipeline.
- Streamlit page config: The `set_page_config` function customizes the app’s layout, page title, and sidebar for a user-friendly interface.
Now your environment and required libraries are set. Next, we initialize session state variables to track our data throughout each session.
Step 2: Initialize Session State Variables
Before handling any documents or user input, we must ensure that our Streamlit app can reliably track all data and state throughout a user session.
Streamlit runs each user interaction as a separate script execution, which means any variables stored in the local scope will reset with every button press. To keep the data persistent, Streamlit’s `st.session_state` parameter is the preferred solution. It enables you to store variables that persist across all user interactions in a session, maintaining a smooth experience.
```python
if 'vectorstore' not in st.session_state:
st.session_state.vectorstore = None
if 'document_processed' not in st.session_state:
st.session_state.document_processed = False
if 'chat_history' not in st.session_state:
st.session_state.chat_history = []
if 'paper_summary' not in st.session_state:
st.session_state.paper_summary = None
```
Below is a breakdown of what each parameter in the code above does:
- `vectorstore`: This holds the persistent retrieval database (Chroma or FAISS) built from the uploaded research paper. It’s initialized as None and gets updated after successful document processing.
- `document_processed`: A simple boolean flag to indicate whether the current document has been processed and is ready for Q&A.
- `chat_history`: This parameter maintains the full record of user and AI messages for a multi-turn conversational interface.
- `paper_summary`: This stores the LLM-generated summary of the uploaded paper, so users can always revisit or expand upon the core findings.
Once our session states are initialized, we can work on uploading and extracting text from the PDFs.
Step 3: Upload the PDF and Extract Text
To analyze a research paper, we first need to get its full text into a format the AI can process. In this step, we define a helper function that extracts text from any uploaded PDF, preparing it for further analysis and chunking.
```python
def extract_text_from_pdf(uploaded_file):
try:
pdf_reader = PyPDF2.PdfReader(uploaded_file)
text = ""
for page in pdf_reader.pages:
text += page.extract_text() + "\n"
return text
except Exception as e:
st.error(f"Error extracting text from PDF: {str(e)}")
return None
```
This function uses `PyPDF2.PdfReader` to open and process the uploaded PDF file, iterating through each page and extracting the text with the `.extract_text()` method. All page texts are concatenated into a single string for downstream processing. If extraction fails, then the exception is caught and a Streamlit error message is shown.
Step 4: Generate a Paper Summary
After extracting the research paper text, the next step is to provide users with a high-level summary of the document. Here, we use an LLM (Large Language Model) to generate a structured summary that captures all the key sections and findings from the paper.
```python
def generate_paper_summary(text):
try:
llm = OpenAI(temperature=0.3, max_tokens=1000)
summary_prompt = (
"You are an expert research analyst. Please provide a comprehensive summary of this research paper. "
"Include the following sections:\n\n"
"1. **Title and Authors** (if available)\n"
"2. **Abstract/Summary** - Main research question and objectives\n"
"3. **Methodology** - How the research was conducted\n"
"4. **Key Findings** - Main results and discoveries\n"
"5. **Contributions** - What new knowledge or insights this paper provides\n"
"6. **Limitations** - Any limitations mentioned by the authors\n"
"7. **Future Work** - Suggested future research directions\n\n"
"Please be thorough but concise. Use clear headings and bullet points where appropriate.\n\n"
f"Research Paper Text:\n{text[:8000]}\n\n" # Limit text to avoid token limits
"Summary:"
)
summary = llm.invoke(summary_prompt)
return summary
except Exception as e:
st.error(f"Error generating summary: {str(e)}")
return None
```
The `generate_paper_summary()` function takes the extracted paper text and crafts a structured prompt for the LLM to produce a section-wise summary. Some of the key points from this function are:
- Only the first 8000 characters are passed to the model to avoid exceeding token limits.
- The LLM is invoked using a controlled temperature (0.3) and a defined `max_tokens` value for high-quality output.
- Any errors encountered during LLM invocation are displayed in the Streamlit UI for easy error handling.
In this step, we built a function to generate an initial summary of the uploaded paper. Next, we need a vector index to store the extracted text.
Step 5: Build a Vector Store
With the paper text and summary in hand, the next step is to prepare the document for RAG by chunking it into smaller passages and storing these chunks in a vector database. This setup is essential for efficient similarity search and retrieval for downstream Q&A.
```python
def cleanup_chroma_db():
try:
if os.path.exists("./chroma_db"):
shutil.rmtree("./chroma_db")
except Exception as e:
st.warning(f"Could not clean up ChromaDB directory: {str(e)}")
def process_document(text):
try:
cleanup_chroma_db()
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
docs = splitter.create_documents([text])
try:
vectorstore = Chroma.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(),
collection_name="research_papers"
)
return vectorstore
except Exception as chroma_error:
st.warning(f"ChromaDB failed, trying FAISS: {str(chroma_error)}")
vectorstore = FAISS.from_documents(
documents=docs,
embedding=OpenAIEmbeddings()
)
return vectorstore
except Exception as e:
st.error(f"Error processing document: {str(e)}")
cleanup_chroma_db()
return None
```
This step includes ` cleanup_chroma_db()` function and `process_document()` function. Let’s dive deeper into what each does:
- Chunking the Document: The `RecursiveCharacterTextSplitter` class in the `process_document()` function divides the document into overlapping chunks. Overlap helps preserve context between adjacent chunks, which improves answer accuracy for queries.
- Embeddings: Each chunk is converted into an embedding vector using `OpenAIEmbeddings()`, enabling semantic search that is a retrieval based on meaning rather than exact text match.
- Vector Database: The code first tries to use Chroma, a vector database for local, persistent storage and fast retrieval. If Chroma fails, the function gracefully falls back to FAISS, which is an in-memory vector store. Note that this step is optional, and you can use FAISS or any other vector database of your choice.
- Database Cleanup: The `cleanup_chroma_db()` helper function ensures that any prior ChromaDB artifacts are removed, preventing index conflicts and stale data. While optional, it’s a useful practice based on personal debugging experience and helps maintain a clean environment.
Step 6: Define CrewAI Agents and Tasks
Now that we have a vector store filled with semantically indexed passages from the research paper, next we define our agents, each with a specific role and skillset, and define the “tasks” they perform and how data flows between them.
```python
def retrieval_action(question, vectorstore):
results = vectorstore.similarity_search(question, k=5)
return "\n\n".join([f"Passage {i+1}: {doc.page_content}" for i, doc in enumerate(results)])
def generation_action(inputs):
if isinstance(inputs, dict):
question = inputs.get("user", "")
context = inputs.get("Retriever", "")
else:
question = "User question not found in inputs"
context = str(inputs)
prompt = (
"You are an expert research analyst. You have been given a specific research paper and asked a question about it. "
"Based on the retrieved passages from the research paper, provide a detailed answer with numbered citations. "
"Use only the information from the provided passages to answer the question.\n\n"
f"USER QUESTION: {question}\n\n"
f"RELEVANT PASSAGES FROM THE RESEARCH PAPER:\n{context}\n\n"
"INSTRUCTIONS:\n"
"1. Answer the question based ONLY on the provided passages from the research paper\n"
"2. Use numbered citations [1], [2], etc. for each key point you reference\n"
"3. If the passages don't contain enough information to answer, say so clearly\n"
"4. Be specific and reference the actual content from the paper\n"
"5. Focus on the key findings, results, and conclusions mentioned in the passages\n"
"6. If asked about key findings, look for results, outcomes, discoveries, or conclusions\n\n"
"ANSWER:"
)
llm = OpenAI(model = ‘gpt-3.5-turbo-instruct’ , temperature=0.2, max_tokens=1500)
return llm.invoke(prompt)
def create_crew(vectorstore, status_callback=None):
def retrieval_wrapper(question):
if status_callback:
status_callback("Searching for relevant passages in the research paper...")
result = retrieval_action(question, vectorstore)
if status_callback:
status_callback("Found relevant passages for analysis")
return result
def generation_wrapper(inputs):
if status_callback:
status_callback("Analyzing retrieved passages and generating comprehensive answer...")
result = generation_action(inputs)
if status_callback:
status_callback("Generated detailed answer with citations")
return result
retriever = Agent(
role="Retriever",
goal="Retrieve relevant passages from the research paper",
backstory="You are an expert at finding relevant information in research papers",
action=retrieval_wrapper,
verbose=True
)
generator = Agent(
role="Generator",
goal="Generate comprehensive answers based on retrieved passages",
backstory="You are an expert research analyst who provides detailed, citation-based answers",
action=generation_wrapper,
verbose=True
)
retrieval_task = Task(
description="Retrieve relevant passages from the research paper for the user's question",
agent=retriever,
expected_output="Relevant passages from the research paper that can answer the user's question"
)
generation_task = Task(
description="Generate a comprehensive answer with citations based on the retrieved passages from the research paper",
agent=generator,
expected_output="A detailed answer with numbered citations based on the research paper content",
context=[retrieval_task]
)
crew = Crew(
agents=[retriever, generator],
tasks=[retrieval_task, generation_task],
verbose=True
)
return crew
```
So, how does each agent work? Let’s break it down step by step:
- `retrieval_action()` function: This function uses the vectorstore to perform a semantic similarity search for the user’s question, returning the top-5 relevant passages (k=5).
- `generation_action()` function: It composes a detailed prompt for the LLM, providing both the user question and the retrieved context, instructing the model to generate a well-cited answer only using the provided evidence. This pattern reduces hallucination and enforces grounding. Note that we used the `gpt-3.5-turbo-instruct` model for this demo, but you can opt for any model compatible with the OpenAI API.
- Agent and Task: The `Retriever Agent` is responsible for fetching relevant text from the vector store. The `Generator Agent` uses the retrieved passages to write a detailed and structured answer with proper citations. Each agent is paired with a Task, describing its function and expected output.
- Data Flow: CrewAI lets you chain tasks, so the output of the Retriever task flows directly into the Generator, creating a simple two-stage agentic pipeline.
Step 7: Build the Streamlit UI
This main loop ties the entire workflow into a user-friendly research assistant, using Streamlit for interactive UI and CrewAI to manage agentic logic and explainable AI execution.
```python
def main():
st.title("Research Paper Analyst")
st.markdown("Upload a research paper and ask questions about it using AI-powered analysis.")
with st.sidebar:
st.header("Document Upload")
uploaded_file = st.file_uploader(
"Choose a PDF file",
type="pdf",
help="Upload a research paper in PDF format"
)
if uploaded_file is not None:
st.info(f"File uploaded: {uploaded_file.name}")
if st.button("Process Document", type="primary"):
with st.spinner("Processing document and generating summary..."):
text = extract_text_from_pdf(uploaded_file)
if text:
summary = generate_paper_summary(text)
if summary:
st.session_state.paper_summary = summary
vectorstore = process_document(text)
if vectorstore:
st.session_state.vectorstore = vectorstore
st.session_state.document_processed = True
st.info("Document processed successfully! Summary generated and ready for questions.")
else:
st.error("Failed to process document.")
else:
st.error("Failed to extract text from PDF.")
if not st.session_state.document_processed:
st.info("Please upload and process a PDF document using the sidebar to get started.")
else:
with st.expander("Paper Summary", expanded=False):
if st.session_state.paper_summary:
st.markdown(st.session_state.paper_summary)
else:
st.warning("Summary not available.")
st.subheader("Ask Questions About Your Research Paper")
for message in st.session_state.chat_history:
with st.chat_message(message["role"]):
st.write(message["content"])
if prompt := st.chat_input("Ask a question about the research paper..."):
st.session_state.chat_history.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
with st.chat_message("assistant"):
progress_container = st.container()
execution_trace_container = st.expander("Execution Details", expanded=False)
with progress_container:
st.info("Initializing AI agents...")
try:
status_placeholder = st.empty()
trace_placeholder = execution_trace_container.empty()
execution_steps = []
def log_step(step):
execution_steps.append(step)
with trace_placeholder:
for i, s in enumerate(execution_steps, 1):
st.write(f"{i}. {s}")
def status_callback(message):
status_placeholder.info(message)
log_step(message)
status_placeholder.info("Initializing AI agents...")
log_step("CrewAI agents initialized")
crew = create_crew(st.session_state.vectorstore, status_callback)
status_placeholder.info("Starting AI analysis...")
log_step("CrewAI execution started")
status_placeholder.info("Retrieving relevant passages...")
retrieved_passages = retrieval_action(prompt, st.session_state.vectorstore)
log_step("Retrieved relevant passages from the research paper")
status_placeholder.info("Generating comprehensive answer...")
inputs = {
"user": prompt,
"Retriever": retrieved_passages
}
response = generation_action(inputs)
log_step("Generated detailed answer with citations")
status_placeholder.info("Analysis complete!")
st.session_state.chat_history.append({"role": "assistant", "content": response})
st.markdown("### AI Analysis Result:")
st.write(response)
with execution_trace_container:
st.markdown("### Execution Summary:")
st.info("**Retriever Agent**: Found relevant passages from the research paper")
st.info("**Generator Agent**: Created comprehensive answer with citations")
st.info(f"**Total Steps**: {len(execution_steps)}")
st.markdown("### Detailed Execution Trace:")
for i, step in enumerate(execution_steps, 1):
st.write(f"{i}. {step}")
except Exception as e:
error_msg = f"Error generating response: {str(e)}"
st.error(error_msg)
st.session_state.chat_history.append({"role": "assistant", "content": error_msg})
if st.button("Clear Chat History"):
st.session_state.chat_history = []
st.rerun()
if __name__ == "__main__":
main()
```
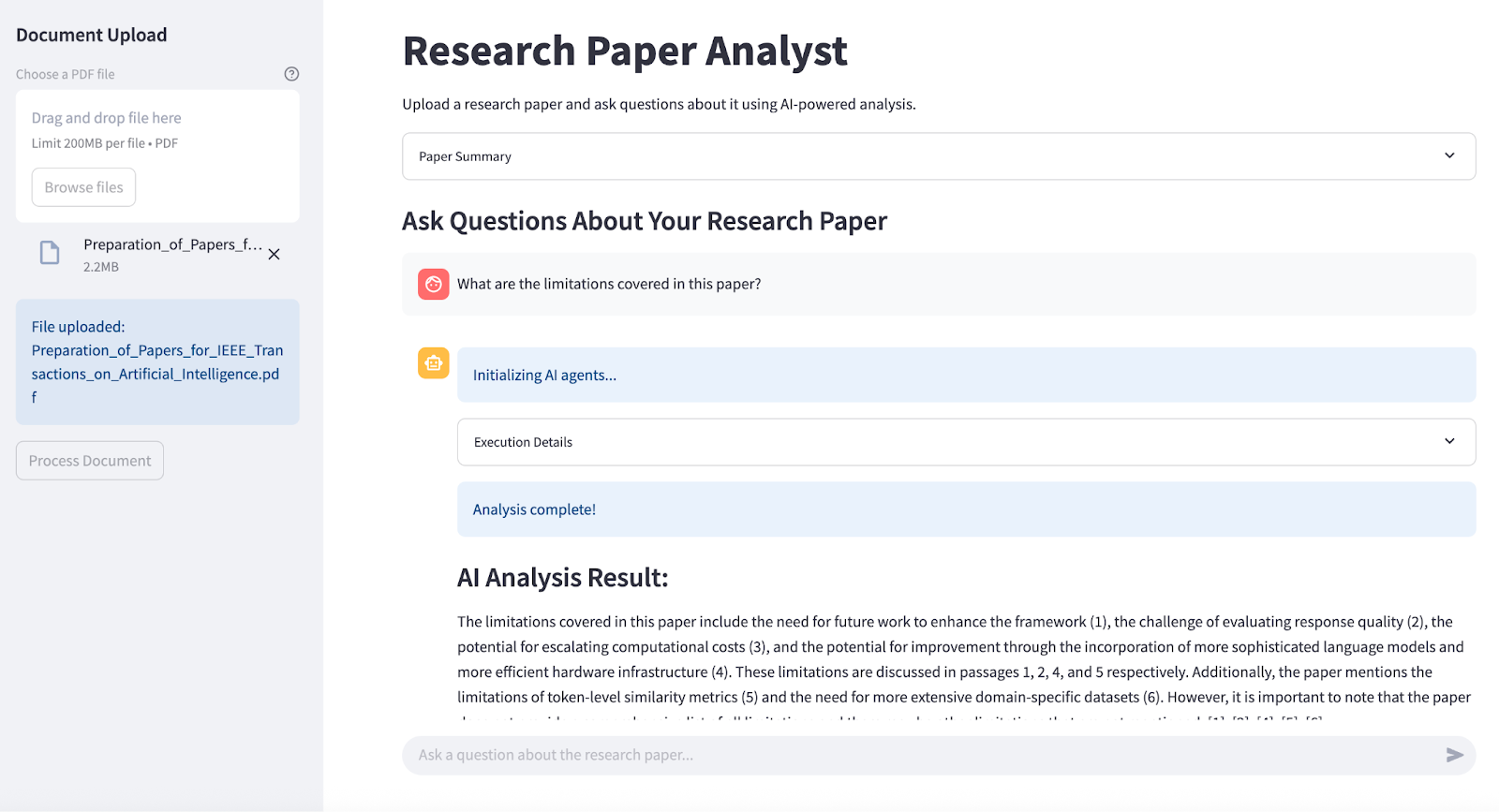
After you upload a research paper (PDF) in the sidebar, a single click extracts the text, generates a summary, and builds the document’s embeddings for instant Q&A. All key states, like the processed document, summary, and conversation history, are stored in memory, so you can chat with the AI about the paper in a multi-turn interface.
Every question spins up CrewAI agents, who retrieve the most relevant passages and generate citation-rich answers. The app shows progress and execution details for full transparency, while a “Clear Chat” button lets you reset and start fresh anytime.
To try it yourself, save the code as `app.py` and launch:
```bash
streamlit run app.py
```
Step 8: Extend to Multi-Agent Workflow (Optional)
As your needs evolve from simple Q&A to more sophisticated research tasks, CrewAI allows you to orchestrate multi-agent workflows with ease. In this step, you’ll see how to extend your research paper analyzer from a single retrieval-generation pipeline to a modular, multi-agent system. Simply, replace the `create_crew()` function in step 6 with this extended crew multi-agent workflow.
```python
def create_advanced_crew(vectorstore, status_callback=None):
def retrieval_wrapper(question):
if status_callback:
status_callback("Searching for relevant passages in the research paper...")
result = retrieval_action(question, vectorstore)
if status_callback:
status_callback("Found relevant passages for analysis")
return result
def generation_wrapper(inputs):
if status_callback:
status_callback("Analyzing retrieved passages and generating comprehensive answer...")
result = generation_action(inputs)
if status_callback:
status_callback("Generated detailed answer with citations")
return result
retriever = Agent(
role="Research Retriever",
goal="Retrieve relevant passages from research papers",
backstory="You are an expert at finding relevant information in research papers",
action=retrieval_wrapper,
verbose=True
)
generator = Agent(
role="Research Analyst",
goal="Generate comprehensive answers based on retrieved passages",
backstory="You are an expert research analyst who provides detailed, citation-based answers",
action=generation_wrapper,
verbose=True
)
retrieval_task = Task(
description="Retrieve relevant passages from the research paper for the user's question",
agent=retriever,
expected_output="Relevant passages from the research paper that can answer the user's question"
)
generation_task = Task(
description="Generate a comprehensive answer with citations based on the retrieved passages from the research paper",
agent=generator,
expected_output="A detailed answer with numbered citations based on the research paper content",
context=[retrieval_task]
)
crew = Crew(
agents=[retriever, generator],
tasks=[retrieval_task, generation_task],
verbose=True
)
return crew
```
For this extended workflow to work, we need the following:
- Agent role specialization: The architecture separates responsibilities between two dedicated agents: the `Research Retriever` is responsible solely for high-recall and semantic document retrieval, while the `Research Analyst` focuses on generating citation-grounded answers.
- Chained task execution: Each agent is assigned a `Task` object, with strict data flow such that the output of the retrieval task becomes the direct context for the generation task. This allows for future chaining, like adding critique or fact-check steps by simply extending the task list and connecting their contexts.
- Status reporting and observability: Both the retrieval and generation wrappers accept a `status_callback` parameter for real-time updates to appear in the UI or logs for stepwise tracing, and easier debugging in production.
- Scalability and extensibility: You can define additional agents, assign them roles and tasks, and add them to the `Crew` composition, with no changes to existing logic for increasingly complex, multi-stage agentic pipelines.

Conclusion
In this tutorial, we built a RAG assistant that lets users upload a paper, ask a question, and get answers tied to the exact passages. It’s a minimal demo by design, which can be expanded into a multi-agent workflow with more than a retriever and a generator.
You can evaluate your extended system with 5–10 QA pairs (tracking accuracy, citation coverage, and recall), add a reranker for sharper retrieval, introduce a fact-checker agent, support multiple PDFs, and log traces, latency, and cost. This RAG agent already combines robust retrieval, structured answer synthesis, and a clean Streamlit UI that act as a foundation for production-grade tools. If you’d like to go deeper into building sophisticated AI workflows, Turing College’s AI Engineering course covers techniques like LangChain, RAG, and multi-agent systems, to help you expand and refine what you’ve built in this tutorial.
Want to become an AI engineer?
Learn the skills that matter on our hands-on Software & AI Engineering programme.