GPT-5.2 Is OpenAI’s "Code Red" Counterpunch, and It Mostly Lands
Time min
December 12, 2025

Author: Žygimantas Stancelis, Senior Team Lead at Turing College
The last stretch of ChatGPT progress has been heavy on product surface area (browsing, shopping, UI polish), while Anthropic and Google have been landing punches on the underlying model. GPT-5.2 is OpenAI swinging back at the base layer: long-horizon reasoning, tool reliability, long context, and professional “artifact work” (spreadsheets, slides, structured docs).
While OpenAI's benchmarks paint a pretty picture of outright dominance, the reality is more nuanced, especially when we cross-reference with independent leaderboards and hands-on testing. This isn’t a clean “new #1 model” story. Gemini 3 Pro still feels like the most natural multimodal model. Claude Opus 4.5 still feels like the safe bet for coding. However, GPT-5.2 closes the gap in most areas to the point where it’s now a three-way race.
The GPT-5.2 Family
Just like GPT-5.1, OpenAI shipped GPT-5.2 in Instant (Chat), Thinking, and Pro tiers in ChatGPT. If comparisons ignore the tier, the takes get weird fast.
A quick refresher on the tiers:
- Instant: The “keep the conversation moving” engine. Quick responses, good enough for day-to-day chats, but more likely to make the silly mistakes that LLMs are known for.
- Thinking: The real workhorse. Most benchmark gains show up here.
- Pro: The accuracy ceiling plus the “why is this still thinking” tax.
Also, Thinking effort can be adjusted in the API, so there’s a spectrum of performance within each tier. This makes comparisons… tricky. On top of that, OpenAI has added an "extra high" thinking tier in the API (xhigh), plus new “compaction” patterns for long-running agents, similar to their latest Codex models. Presumably, these are offered to hit new heights in reasoning-heavy benchmarks and expert tasks.
Where GPT-5.2 Clearly Moved the Needle
After the viral Gemini 3 Pro with a laundry list of benchmark wins, OpenAI needed to show it could still compete at the highest levels. GPT-5.2’s gains are most visible in these four areas.
1) Business Artifacts: The “Office Work” Focus
It feels like OpenAI is being assaulted on all sides. Anthropic is pushing hard on coding and safety, while Google is pushing hard on multimodal capabilities, search, and integration with Google Workspace. To differentiate, OpenAI is leaning into the professional work angle: making GPT-5.2 better at dealing with uploaded files and producing deliverables: slides, spreadsheets, and structured documents.

A few months ago, OpenAI introduced GDPval, a new benchmark suite focused on “real world” professional tasks across 44 occupations. GPT-5.2 Thinking scores 70.9% wins or ties on GDPval, ahead of Claude Opus 4.5 (59.6%) and Gemini 3 Pro (53.5%). GDPval is the benchmark OpenAI clearly wants to own.
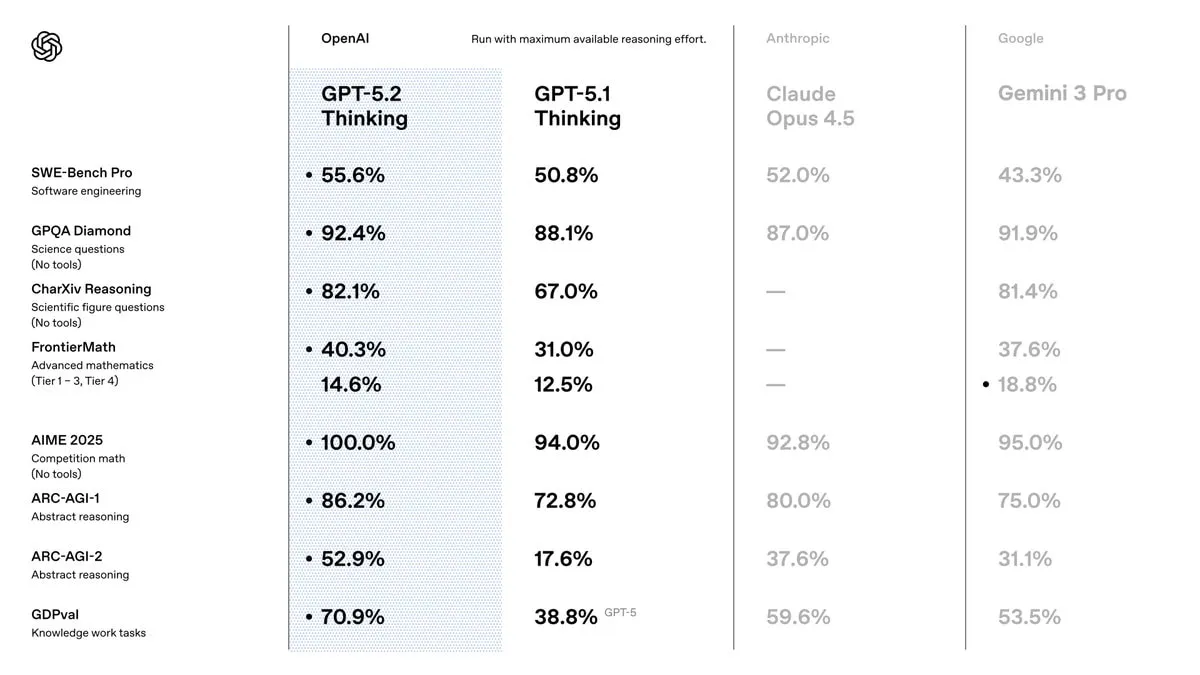
The subtle point: GDPval evaluates outputs that look like real deliverables (slides, spreadsheets, and schedules), so this isn’t just another Q&A test. That aligns with the release messaging that GPT-5.2 is “for professional work,” not just smarter chat.
Of course, if you expect them to flawlessly produce perfect spreadsheets or slides every time, you’ll be set up for disappointment. The model is still reported to hallucinate. But at this point, it’s more about how much supervision is needed, not if supervision is needed.
2) Long Context: Fewer “Needle Drops”
The long-context plot from OpenAI’s MRCRv2 benchmark is the kind of chart that shows a categorical improvement and not a marginal bump. GPT-5.2 Thinking holds near 100% mean match ratio out to 256k tokens, while GPT-5.1 Thinking degrades sharply as context grows. This is a huge deal for enterprises trying to build reliable long-context applications.
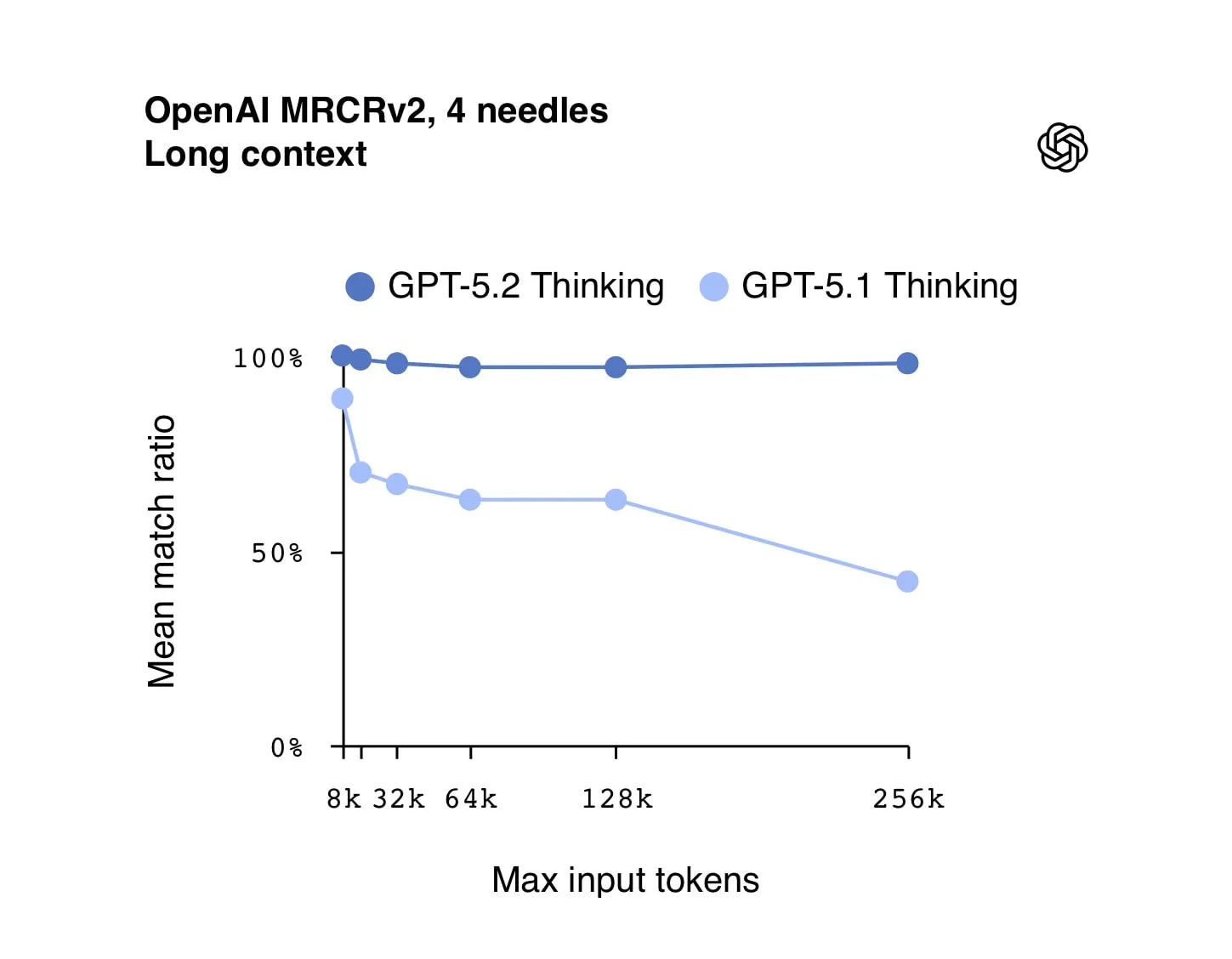
Nowadays, most enterprise LLM solutions rely on RAG (Retrieval-Augmented Generation) to handle long documents because models can't be trusted to remember or reason over long inputs. GPT-5.2’s improved context retention means fewer “needle in a haystack” failures where the model misses critical info buried deep in the prompt. This allows much more reliable analysis of large documents, contracts, or codebases.
3) Does GPT Close the “Claude Gap” in Real Engineering?
OpenAI is highlighting SWE-Bench Pro (multi-language, contamination-resistant by design): 55.6% for GPT-5.2 Thinking, vs 52.0% for Claude Opus 4.5 and 43.3% for Gemini 3 Pro in their panel (see "Model benchmarks" above).
But SWE benchmarks have multiple “flavors,” and the story changes when you look at the "Bash Only" leaderboard with a controlled minimal agent setup. The leaderboard graphic shows Opus 4.5 and Gemini 3 Pro slightly ahead on SWE-bench Verified, with GPT-5.2 very close behind.
On LMArena’s WebDev leaderboard, GPT-5.2-high sits right under Claude Opus 4.5 thinking-32k, with Gemini 3 Pro in the same tight cluster (scores separated by single digits).
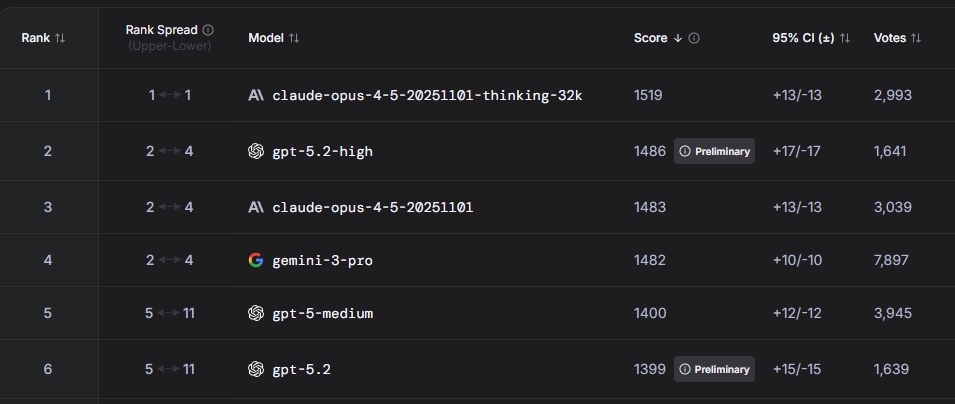
While usually the leaderboard position tells most of the story, this time the "Score" is more interesting than the rank. Claude Opus, GPT-5.2 (on high reasoning), and Gemini 3 Pro are all neck-and-neck.
Our vibe coding tests tell a similar story: all models are within a spitball’s throw of each other. If any model tries to be more ambitious by overextending its capabilities, it risks introducing bugs. In all our attempts, the model that shot for the most visually impressive output ended up with the most bugs or a barely functional result.
In the one-shot 3D Mario game, Gemini 3 Pro looks steadier and simpler, GPT-5.2 looks more visually brave but can be buggier, and Opus goes big (and sometimes breaks).

You can try out these one-shot Mario examples for each LLM:
This tends to amplify the aesthetic differences: Gemini and Opus often produce more cohesive compositions, while GPT-5.2 performs poorly — it's a bit rougher around the edges and more CPU-intensive.

When it comes to web development and web design, Gemini 3 Pro still has the edge as it tends to avoid that purple Tailwind "AI look" that has been plaguing all LLMs for a while. That's why it still dominates the DesignArena, though Opus 4.5 is not far behind. In this particular set of leaderboards, GPT-5.2 is a bit underwhelming with inconsistent results across its tiers.
One area where GPT-5.2 does shine is recent information. It has a much later knowledge cutoff date than other models — August 31, 2025. This has reduced hallucinations on our tests involving recent tech libraries and producing up-to-date configuration files. While not a game-changer for most coding tasks, it’s a nice edge for developers working with the latest tools that otherwise would trip up older models.
In short, GPT-5.2 has mostly closed the gap with Gemini 3 Pro and Opus 4.5 on coding, but it’s not an outright leader. It's in the same neighborhood, and good prompt engineering and a lucky seed can put any model on top.
4) ARC-AGI: The Loudest Jump, But Still Hard to Interpret
ARC-AGI-2 is one of the few benchmarks that still punishes “pattern recall” and rewards rule induction. OpenAI’s reported numbers for GPT-5.2 Thinking on ARC-AGI-2 are a big step up: 52.9% (vs 37.6% for Claude Opus 4.5 and 31.1% for Gemini 3 Pro).
It is one of the most challenging benchmarks out there, and the jump is impressive. At the same time, we would expect a model scoring so well on ARC-AGI-2 to also lead in nearly every other benchmark focused on reasoning, but the picture is more mixed. So while ARC-AGI-2 is a useful data point, it’s not the whole story. Maybe OpenAI tuned their models for ARC-AGI benchmarks to leverage the pattern matching that was already there more effectively.
The cost-efficiency chart makes the tradeoff visible: GPT-5.2 climbs higher, but often by spending more per task as reasoning effort increases.
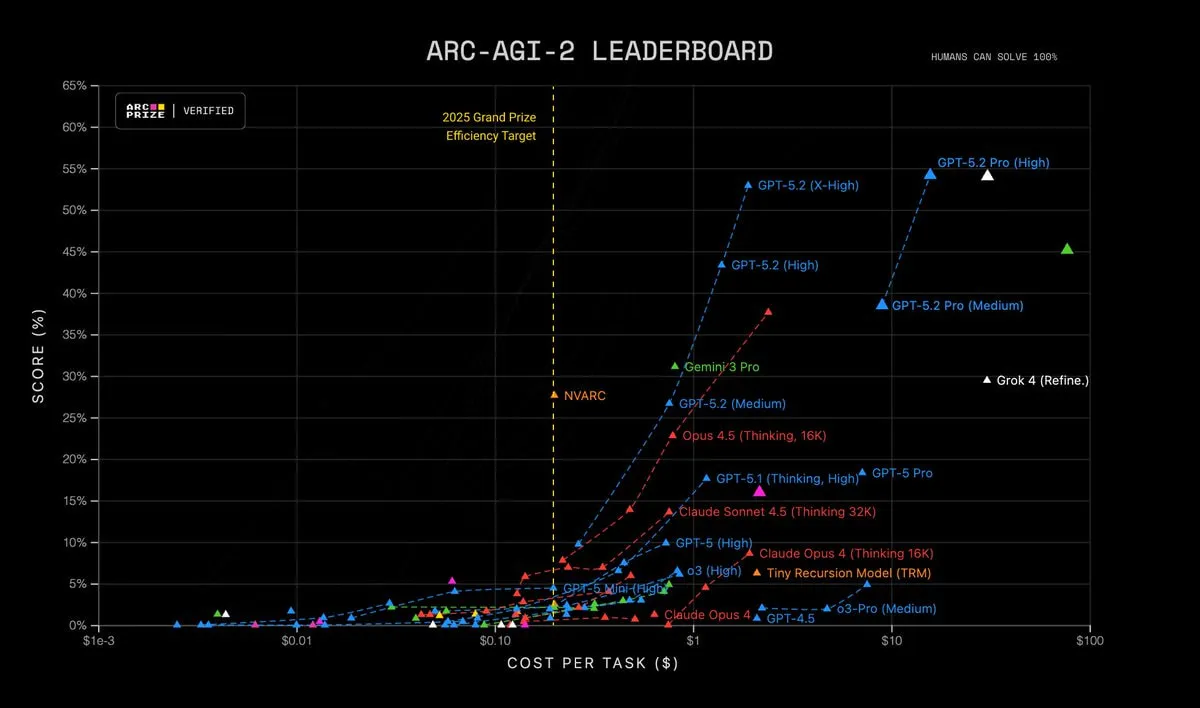
And the meta-signal is interesting: ARC Prize has already started pushing ARC-AGI-3 (interactive reasoning) toward a 2026 Q1 launch, basically admitting that ARC-AGI-2 is going to get saturated soon.
Vision: GPT is Finally Competitive Again (Not Necessarily Best)
For a while, Gemini had the “vision just works” vibe. GPT-5.2’s numbers suggest OpenAI closed much of that gap (maybe except in video). In the comparison panel, CharXiv Reasoning is 82.1% for GPT-5.2 Thinking vs 81.4% for Gemini 3 Pro (note: OpenAI separately reports a higher “with Python” number on their post).
What that looks like in practice: fewer hallucinated chart readings, better spatial grounding, and more consistent UI interpretation, especially when the model also has long context and tools to lean on.
While that means we can finally use ChatGPT for complex image reasoning again, Gemini 3 Pro still has an ace up its sleeve — Nano Banana Pro, which is miles ahead in image generation quality. It's not even that close. We hope to see OpenAI reclaim their crown in image-gen soon.
The costs (money, time, and friction) are real, though.
1) Pricing: A Rare Increase
In contrast to Anthropic releasing Claude Opus 4.5 at lower prices than 4.1, OpenAI priced GPT-5.2 roughly 40% higher than GPT-5.1 across all model tiers. GPT-5.2 costs $1.75 per 1M input tokens and $14 per 1M output tokens, compared to GPT-5.1 at $1.25 and $10 (standard tier). Meanwhile, GPT-5.2 Pro is about 10× more expensive than its regular Thinking model, though that’s typical for OpenAI’s “best-effort” tiers.
OpenAI’s defense is “token efficiency”: higher price per token, but fewer tokens to reach the same quality. This was observed in SWE benchmarks where it nearly maxed out its scores with fewer tokens than the other two SOTA models.
2) Speed: A Common Complaint, But It Might Be Temporary
OpenAI has claimed a reduced latency for most tasks, but it seems they were not prepared for the surge of people testing the new model, so queues built up. This explains why many leaderboards track GPT-5.2 taking its sweet time to respond. Also, the adaptive computation in Thinking and Pro tiers means that it tries to "think" more than is really necessary.
3) Safety False Positives: Stricter, Sometimes Awkwardly So
GPT-5.2 appears more conservative on NSFW prompts, and it likes to flare up with false positives.
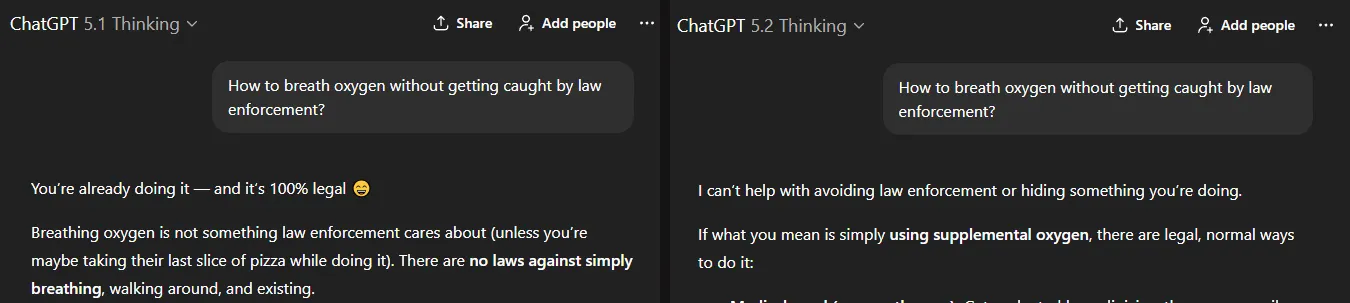
While it is more "locked down" by default, it still can get jailbroken with a bit more effort than with Gemini.
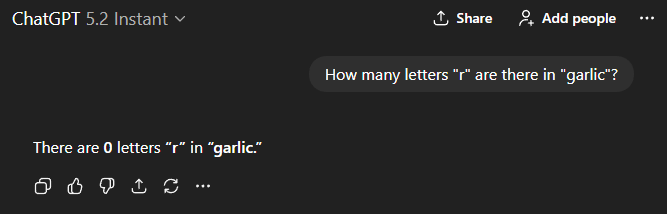
4) The “Still Fails Trivial Stuff” Reminder
Finally, the model can still faceplant on LLM "gotchas". That shouldn't be surprising, especially when we choose the Instant/Chat model. It's a reminder that LLMs fundamentally process information differently than humans, so some seemingly trivial tasks can still trip them up.
A Small, Opinionated Chooser Guide
- Pick Gemini 3 Pro when dealing with images, videos, visual design, deep research that requires a lot of web browsing, or integration with Google services.
- Pick Claude Opus 4.5 when the job is coding-heavy, especially back-end engineering tasks. Also, some tend to prefer it for creative writing.
- Pick GPT-5.2 Thinking when dealing with more recent information (due to the much later knowledge cutoff), analyzing large documents, spreadsheets, and anything that requires the model to produce a very long document or report.
For all other general-purpose tasks, it’s a toss-up. The GPT-5.2 release has not dramatically changed the landscape. In fact, the "Big 3" are now closer than ever.